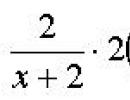Ülesannete lahendamine ökonomeetrias. Lahendus ja analüüs, kuidas ökonomeetriast keskmist leida
Oletame, et oleme leidnud need hinnangud ja saame kirjutada võrrandi:
ŷ = a + bX,
kus a- regressioonikonstant, regressioonijoone ja telje lõikepunkt OY;
b- regressioonikordaja, suhet iseloomustav regressioonisirge kalle DY¤DX;
ŷ on seletatava muutuja teoreetiline väärtus.
Nagu teada, saab paari regressiooni korral matemaatilise mudeli tüübi valida kolme tüüpi:
1. Graafika.
2. Analüütiline.
3. Eksperimentaalne.
Graafilist meetodit saab kasutada vaadeldavaid väärtusi kirjeldava funktsiooni valimiseks. Algandmed kantakse koordinaattasandile. Faktoratribuudi väärtused kantakse abstsissteljele ja saadud atribuudi väärtused ordinaatteljele. Punktide asukoht näitab ühenduse ligikaudset kuju. Reeglina on see suhe kõverjooneline. Kui selle joone kõverus on väike, siis võime nõustuda sirgjoonelise ühenduse olemasolu hüpoteesiga.
Esitagem tarbimisfunktsiooni hajuvusdiagrammina. Selleks joonistame koordinaatsüsteemis abstsissteljele tulu väärtuse ja ordinaatteljel - tingimusliku toote tarbimiskulu. Väärtuste kogumitele "sissetulek - tarbimiskulutused" vastavate punktide asukoht näitab seose ligikaudset vormi (joonis 1).
Visuaalselt ei ole diagrammi järgi peaaegu kunagi võimalik parimat sõltuvust üheselt nimetada.
Liigume edasi valitud funktsiooni parameetrite hindamise juurde a ja b vähimruutude meetod.
Hindamisprobleemi saab taandada "klassikaliseks" miinimumi leidmise probleemiks. Muutujad osutuvad nüüd hinnanguteks a ja b kavandatava ühenduse tundmatud parameetrid juures ja X. Mis tahes funktsiooni väikseima väärtuse leidmiseks peate esmalt leidma esimest järku osatuletised. Seejärel võrdsustage igaüks neist nulliga ja lahendage saadud võrrandisüsteem muutujate suhtes. Meie puhul on selline funktsioon hälvete ruudu summa - S ja muutujad a ja b. See tähendab, et peame leidma = 0 ja = 0 ning lahendama saadud võrrandisüsteemi suhtes a ja b.
Tuletame parameetrite hinnangud vähimruutude meetodi abil, eeldades, et piirangu võrrandil on vorm ŷ = a + bX. Siis funktsioon S on vorm
. Funktsiooni eristamine S peal a, saame esimese normaalvõrrandi suhtes diferentseerides b on teine normaalvõrrand. ..Pärast sobivaid teisendusi saame:
(*)Normaalvõrrandisüsteemi koostamiseks kehtivad lihtsustatud reeglid. Rakendame need lineaarsele funktsioonile:
1) Korrutage võrrandi iga liige ŷ = a + bX koefitsiendi järgi esimese parameetri juures ( a), see tähendab ühiku kohta.
2) Paneme iga muutuja ette liitmismärgi.
3) Korrutame võrrandi vaba liikme arvuga n.
4) Hankige esimene normaalvõrrand
5) Korrutame algse võrrandi iga liikme teise parameetri koefitsiendiga ( b), see on, X.
6) Paneme iga muutuja ette liitmismärgi.
7) Saame teise normaalvõrrandi
Nende reeglite kohaselt koostatakse mis tahes lineaarfunktsiooni jaoks normaalvõrrandi süsteem. Reeglid sõnastas esmakordselt inglise majandusteadlane R. Pearl.
Võrrandi parameetrid arvutatakse järgmiste valemite abil:
, ,Ehitame tabeli 1 algandmeid kasutades normaalvõrrandite süsteemi (*) ja lahendame selle tundmatute jaoks a ja b:
1677=11*a+4950*ba = -3309
790 400=4950*a+2 502 500*bb = 7,6923
Regressioonivõrrand näeb välja selline:
ŷ \u003d -3309 + 7,6923 x ,
Võrdleme kauba A tegelikke ja hinnangulisi tarbimiskulusid (tabel 2).
Tabel 2 Kaupade tarbimise kulutuste tegelike ja arvestuslike väärtuste võrdlus AGA lineaarse seosega:
| rühma number | Tarbimiskulutused kaubad AGA | Tegelike kulude kõrvalekalle hinnangulisest |
|
| tegelik (y) | asula | absoluutne (u-ŷ) |
|
| 1 | 120 | -1770,54 | 1890,54 |
| 2 | 129 | -1385,92 | 1514,92 |
| 3 | 135 | -1001,31 | 1136,31 |
| 4 | 140 | -616,45 | 756,45 |
| 5 | 145 | -232,08 | 377,08 |
| 6 | 151 | 152,53 | -1,53 |
| 7 | 155 | 537,15 | -382,15 |
| 8 | 160 | 921,76 | -761,76 |
| 9 | 171 | 1306,38 | -1135,38 |
| 10 | 182 | 1690,99 | -1508,99 |
| 11 | 189 | 2075,61 | -1886,61 |
| Kokku | - | - | 0 |
Joonistame saadud funktsiooni graafikule ŷ ja hajuvusdiagramm, kasutades tegelikke väärtusi (y) ja arvutatud väärtusi ( ŷ) .
Arvutatud väärtused erinevad tegelikest, kuna märkide vaheline seos on korrelatsiooniline.
Seoste tiheduse mõõtmiseks kasutatakse korrelatsioonikordajat:
=Tabeli 1 algandmeid kasutades saame:
σ x =158;
σ y = 20,76;
r = 0,990.
Lineaarne korrelatsioonikordaja võib võtta mis tahes väärtuse vahemikus miinus 1 kuni pluss 1. Mida lähemal on korrelatsioonikordaja absoluutväärtus 1-le, seda tihedam on seos tunnuste vahel. Lineaarse korrelatsioonikordaja märk näitab seose suunda - positiivne märk vastab otsesele seosele ja miinusmärk vastab pöördsuhtele.
Järeldus: väärtuste suhe X ja vastavad väärtused juures
lähedane, otsene suhe.
Meie näites d = 0,9801
See tähendab, et kauba maksumuse muutus AGA on 98,01% seletatav sissetulekute muutusega.
Ülejäänud 1,99% võib tuleneda järgmistest põhjustest:
1) ebapiisavalt hästi valitud suhtlusvorm;
2) mõju muude arvestamata tegurite sõltuvale muutujale.
Hüpoteeside statistiline kontrollimine.
Esitasime nullhüpoteesi, et regressioonikordaja on statistiliselt ebaoluline:
H 0 : b = 0.
Regressioonikordaja statistilist olulisust kontrollitakse kasutades t- Üliõpilase kriteerium. Selleks määrame esmalt ruutude jääksumma
s 2 ost= å (y i – ŷ i) 2
s 2 ost = 1,3689.
ja selle standardhälve
s = 0,39. se ( b ) = 0,018.
tegelik väärtus t- Regressioonikordaja õpilase test:
.tb = 427,35.
Väärtus |t b |>t cr (t cr = 2,26 95% olulisuse taseme korral) võimaldab järeldada, et regressioonikordaja erineb nullist (vastaval olulisuse tasemel) ja seega on olemas mõju (ühendus) X ja y.
Järeldus: tegelik väärtus t-Õpilase kriteerium ületab tabeli, mis tähendab, et nullhüpotees lükatakse tagasi ja 95% tõenäosusega aktsepteeritakse alternatiivne hüpotees regressioonikordaja statistilise olulisuse kohta.
[b– t cr *se( b), b+ t cr *se( b)] – b jaoks 95% usaldusvahemik.
Usaldusvahemik hõlmab parameetri tegelikku väärtust b etteantud tõenäosusega (antud juhul 95%).
7,6516 < b < 7,7329.
Liigume edasi korrelatsiooni- ja määramiskordajate statistilise olulisuse testimise juurde:
r = 0,990;
d = r 2 = 0,9801.
Esitasime nullhüpoteesi, et regressioonivõrrand tervikuna on statistiliselt ebaoluline:
H 0 : r 2 = 0.
Konstrueeritud regressioonimudeli kui terviku statistilise olulisuse hindamine toimub kasutades F- Fisheri kriteerium. tegelik väärtus F- lineaarsete parameetrite paari regressiooni võrrandi kriteeriumid on määratletud järgmiselt:
kus s 2 tegur on teoreetiliste väärtuste dispersioon ŷ (selgitatud variatsioon);
s 2 ülejäänud - ruutude jääksumma;
r 2 - määramiskoefitsient.
tegelik väärtus F- Fisheri kriteerium:
F f = 443,26
Järeldus: lükkame nullhüpoteesi tagasi ja aktsepteerime 95% tõenäosusega alternatiivset hüpoteesi regressioonivõrrandi statistilise olulisuse kohta.
Dispersioon statistikas leitakse tunnuse individuaalsete väärtustena ruudus . Sõltuvalt algandmetest määratakse see lihtsate ja kaalutud dispersioonivalemite abil:
1. (rühmitamata andmete puhul) arvutatakse järgmise valemiga:
2. Kaalutud dispersioon (variatsiooniseeria jaoks):
 kus n on sagedus (kordatavustegur X)
kus n on sagedus (kordatavustegur X)
Näide dispersiooni leidmisest
Sellel lehel on kirjeldatud dispersiooni leidmise standardnäide, selle leidmiseks võite vaadata ka muid ülesandeid
Näide 1. Meil on järgmised andmed 20-liikmelise korrespondentüliõpilase rühma kohta. On vaja koostada tunnusjaotuse intervalljada, arvutada tunnuse keskmine väärtus ja uurida selle dispersiooni
 Koostame intervallide rühmituse. Määrame intervalli vahemiku valemiga:
Koostame intervallide rühmituse. Määrame intervalli vahemiku valemiga:
![]() kus X max on rühmitamise tunnuse maksimaalne väärtus;
kus X max on rühmitamise tunnuse maksimaalne väärtus;
X min on rühmitamise tunnuse minimaalne väärtus;
n on intervallide arv:
Aktsepteerime n=5. Samm on järgmine: h \u003d (192–159) / 5 = 6,6
Teeme intervallrühma
 Edasiste arvutuste jaoks koostame abitabeli:
Edasiste arvutuste jaoks koostame abitabeli:
 X'i on intervalli keskpaik. (näiteks intervalli keskpaik 159 – 165,6 = 162,3)
X'i on intervalli keskpaik. (näiteks intervalli keskpaik 159 – 165,6 = 162,3)
Õpilaste keskmine kasv määratakse aritmeetilise kaalutud keskmise valemiga:
 Dispersiooni määrame valemiga:
Dispersiooni määrame valemiga:
Dispersiooni valemi saab teisendada järgmiselt:

Sellest valemist järeldub, et dispersioon on valikute ruutude keskmise ning ruudu ja keskmise vahe.
Variatsiooniridade hälve võrdsete intervallidega vastavalt momentide meetodile saab arvutada järgmiselt, kasutades teist dispersiooniomadust (jagades kõik valikud intervalli väärtusega). Dispersiooni definitsioon, mis on arvutatud hetkede meetodil, on järgmise valemi järgi vähem aeganõudev:

kus i on intervalli väärtus;
A - tingimuslik null, mida on mugav kasutada kõrgeima sagedusega intervalli keskpunktis;
m1 on esimest järku hetke ruut;
m2 - teise järjekorra hetk
(kui statistilises üldkogumis atribuut muutub nii, et on ainult kaks teineteist välistavat varianti, siis nimetatakse sellist varieeruvust alternatiivseks) saab arvutada valemiga:

Asendades selles dispersioonivalemis q = 1- p, saame:

Dispersiooni tüübid
Kogu dispersioon mõõdab tunnuse varieerumist kogu populatsioonis tervikuna kõigi seda variatsiooni põhjustavate tegurite mõjul. See võrdub atribuudi x üksikute väärtuste kõrvalekallete keskmise ruuduga keskmisest koguväärtusest x ja seda saab määratleda kui lihtsat dispersiooni või kaalutud dispersiooni.
iseloomustab juhuslikku varieerumist, s.t. osa variatsioonist, mis on tingitud arvestamata tegurite mõjust ega sõltu rühmituse aluseks olevast märgitegurist. See dispersioon on võrdne X-rühma atribuudi üksikute väärtuste kõrvalekallete keskmise ruuduga rühma aritmeetilisest keskmisest ja seda saab arvutada lihtsa dispersioonina või kaalutud dispersioonina.
Sellel viisil, rühmasisese dispersiooni mõõdikud tunnuse varieerumine rühmas ja määratakse järgmise valemiga:

kus xi - rühma keskmine;
ni on ühikute arv rühmas.
Näiteks grupisisesed dispersioonid, mida tuleb määrata ülesandes uurida töötajate kvalifikatsiooni mõju töö tootlikkuse tasemele kaupluses, näitavad toodangu kõikumisi igas rühmas, mis on põhjustatud kõigist võimalikest teguritest (seadmete tehniline seisund, tööriistade ja materjalide olemasolu, töötajate vanus, töömahukus jne.), välja arvatud kvalifikatsioonikategooria erinevused (rühmasiseselt on kõigil töötajatel sama kvalifikatsioon).
Grupisiseste dispersioonide keskmine peegeldab juhuslikku, st seda osa variatsioonist, mis toimus kõigi muude tegurite mõjul, välja arvatud rühmitustegur. See arvutatakse järgmise valemiga:

See iseloomustab saadud tunnuse süstemaatilist varieerumist, mis on tingitud rühmituse aluseks oleva tunnusteguri mõjust. See on võrdne grupi keskmiste üldkeskmisest kõrvalekallete keskmise ruuduga. Gruppidevaheline dispersioon arvutatakse järgmise valemiga:

Dispersiooni liitmise reegel statistikas
Vastavalt dispersiooni liitmise reegel kogu dispersioon on võrdne grupisiseste ja rühmadevaheliste dispersioonide keskmise summaga:
![]()
Selle reegli tähendus on see, et kõigi tegurite mõjul tekkiv summaarne dispersioon võrdub kõigi teiste tegurite mõjul tekkivate dispersioonide ja rühmitusteguri mõjul tekkiva dispersiooni summaga.
Kasutades dispersioonide liitmise valemit, on võimalik kahe teadaoleva dispersiooni hulgast määrata kolmas tundmatu ning hinnata ka rühmitava atribuudi mõju tugevust.
Dispersiooniomadused
1. Kui atribuudi kõiki väärtusi vähendatakse (suurendatakse) sama konstantse väärtuse võrra, siis dispersioon sellest ei muutu.
2. Kui atribuudi kõiki väärtusi vähendada (suurendada) sama arv kordi n, siis dispersioon vastavalt väheneb (suureneb) n^2 korda.
Korrelatsioon-regressioonanalüüsi meetod
Kommunikatsiooni mitteparameetrilised näitajad
Juhusliku komponendi heteroskedastilisus
autokorrelatsioon
- Aegridade tasemete autokorrelatsioon. Autokorrelatsiooni kontrollimine korrelogrammi konstruktsiooniga;
Ökonomeetrilised meetodid ekspertuuringute läbiviimiseks
- Dispersioonanalüüsi meetodil kontrollige nullhüpoteesi teguri mõju kohta objekti kvaliteedile.
Saadud lahendus koostatakse Wordi vormingus. Kohe pärast lahendust on malli Excelis allalaadimise link, mis võimaldab kontrollida kõiki saadud näitajaid. Kui ülesanne nõuab lahendust Excelis, siis saad kasutada Exceli statistilisi funktsioone.
Aegridade komponendid
- Analüütilise nivelleerimise teenust saab kasutada aegrea analüütiliseks silumiseks (sirge joonega) ja trendi võrrandi parameetrite leidmiseks. Selleks peate määrama algandmete hulga. Kui andmeid on palju, saab need Excelist sisestada.
- Trendivõrrandi parameetrite arvutamine.
Trendifunktsiooni tüübi valimisel saate kasutada lõplike erinevuste meetodit. Kui üldist trendi väljendatakse teist järku parabooliga, siis saame konstantsed teist järku lõplikud erinevused. Kui kasvukiirused on ligikaudu konstantsed, kasutatakse võrdsustamiseks eksponentsiaalfunktsiooni.
Võrrandi vormi valimisel tuleks lähtuda olemasoleva info hulgast. Mida rohkem parameetreid võrrand sisaldab, seda rohkem peaks olema vaatlusi sama hinnangu usaldusväärsuse astme jaoks. - Silumine libiseva keskmise meetodil. Kasutades
Korrelatsioonisõltuvus faktori x (ühe töövõimelise inimese keskmine toimetulekupiir elaniku kohta päevas) ja sellest tuleneva tunnuse y (keskmine päevapalk) vahel. Lineaarse regressioonivõrrandi parameetrid, regressioonikordaja majanduslik tõlgendamine.
y=f(x)+E ,y t =f(x) – teoreetiline funktsioon, E=y- y t
y t \u003d a + bx - keskmise päevapalga (y) korrelatsioonisõltuvus ühe töövõimelise inimese keskmisest elatusmiinimumist elaniku kohta päevas (x)
a+b  =
=
a  +b
+b  =
=
b=  - regressioonikoefitsient.
- regressioonikoefitsient.
See näitab, kui mitme ühiku võrra muutub keskmine palk (Y) keskmiselt ühe töövõimelise inimese (X) keskmise elatusmiinimum elaniku kohta päevas 1 ühiku võrra.
b=  =
0,937837482
=
0,937837482
See tähendab, et ühe töövõimelise inimese (x) päeva elatusmiinimum elaniku kohta tõuseb 1 ühiku võrra, keskmine päevapalk tõuseb keskmiselt 0,937 ühiku võrra.
a=  -b
-b  , a=135,4166667-0,937837482 86,75=54,05926511
, a=135,4166667-0,937837482 86,75=54,05926511
3) Variatsioonikoefitsient
Variatsioonikoefitsient näitab, kui suur osa SW keskmisest väärtusest on selle keskmine levi.
υ x = δх/x = 0,144982838, υ y = δy/y = 0,105751299
4) Korrelatsioonikordaja
Korrelatsioonikordaja abil hinnatakse ühe töövõimelise inimese keskmise elatusmiinimumi elaniku kohta päevas ja keskmise päevapalga vahelise lineaarse seose tihedust.
rxy \u003d b δх / δy \u003d 0,823674909 kuna rxy ˃0 , siis nimetatakse muutujate vahelist korrelatsiooni otseseks
Kõik see näitab keskmise päevapalga sõltuvust ühe töövõimelise inimese keskmisest elatusmiinimum päevas elaniku kohta.
5) Determinatsioonikoefitsient
Determinatsioonikoefitsienti kasutatakse lineaarse regressiooni võrrandite valiku kvaliteedi hindamiseks.
Determinatsioonikoefitsient iseloomustab efektiivse tunnuse Y (keskmine päevapalk) dispersiooni osakaalu, mida seletatakse efektiivse tunnuse summaarse dispersiooni regressiooniga.
R 2 xy \u003d (∑ (y t - y cf) 2) / (∑ (y - y cf) 2) \u003d 0,678440355, 0,5< R 2 < 0,7 ,
see tähendab, et ühenduse tugevus on märgatav, kõrgele lähedane ja regressioonivõrrand on hästi valitud.
6) Mudeli täpsuse või lähenduse hindamine.
 =1/n ∑ ׀(y i - y t)/y i ׀ 100% - keskmine lähendusviga.
=1/n ∑ ׀(y i - y t)/y i ׀ 100% - keskmine lähendusviga.
Alla 5-7% viga näitab mudeli head valikut.
Kui viga on üle 10%, peaksite mõtlema teist tüüpi mudelivõrrandi valimisele.
Ligikaudne viga  \u003d 0,015379395 100% \u003d 1,53%, mis näitab mudeli head sobivust algandmetega
\u003d 0,015379395 100% \u003d 1,53%, mis näitab mudeli head sobivust algandmetega
7) Dispersioonanalüüsi skeem.
∑(y - y sr) 2 =∑(y t - y sr) 2 + ∑(y i - y t) 2 n on vaatluste arv, m on muutuja x parameetrite arv
|
Dispersiooni komponendid |
Ruudude summa |
Vabadusastmete arv |
Dispersioon vabadusastme kohta |
|
∑(y - y cf) 2 |
S 2 kokku \u003d (∑ (y - y cf) 2) / (n-1) |
||
|
faktoriaalne |
∑(y t - y avg) 2 |
S 2 fakt \u003d (∑ (y t - y cf) 2) / m |
|
|
Jääk |
∑(y i - y t) 2 |
S 2 puhkus \u003d (∑ (y i - y t) 2) / (n-m-1) |
|
Dispersioonanalüüs |
|||
|
Komponendid |
Ruudude summa |
Vabadusastmete arv |
Dispersioon |
|
üldine | |||
|
faktoriaalne | |||
|
jääk | |||
8) Mudeli adekvaatsuse kontrollimine pooltF- Fisheri kriteerium (α=0,05).
Regressioonivõrrandi kui terviku statistilise olulisuse hindamine toimub kasutadesF- Fisheri kriteerium.
H 0 - hüpotees regressioonivõrrandi statistilise olulisuse kohta.
H 1 - regressioonivõrrandi statistiline olulisus.
F hinnanguline määratakse ühe vabadusastme jaoks arvutatud teguri väärtuste ja jääkvariansside suhtest.
F arvutus \u003d S 2 fakt / S 2 ülejäänud \u003d ((∑ (y t - y cf) 2) / m) / ((∑ (y i - y t) 2) / (n-m-1)) \u003d 1669.585177 / 1748.5 = 21.09842966
F tabelikujuline - kriteeriumi maksimaalne võimalik väärtus, mis võiks kujuneda etteantud vabadusastmetega juhuslike tegurite mõjul, s.o. To 1 = m, TO 2 = n- m-1 ja olulisuse tase α (α=0,05)
F-tabel (0,05; 1; n-2), F-tabel (0,05; 1; 10), F-tabel = 4,964602701
Kui aF laud < F arvut , siis hüpoteesH 0 hinnanguliste tunnuste juhuslikkuse kohta lükatakse tagasi ning tunnustatakse nende statistilist olulisust ja regressioonivõrrandi usaldusväärsust. MuiduH 0 ei lükata tagasi ning tunnistatakse regressioonivõrrandi statistilist ebaolulisust ja ebausaldusväärsust. Meie puhul F-tabel< F расч, следовательно признаётся статистическая значимость и надёжность уравнения регрессии.
9) Regressiooni- ja korrelatsioonikordajate statistilise olulisuse hindaminet-Õpilase kriteerium (α=0,05).
Koefitsiendi olulisuse hindamine. regressioon., t on kriteerium Student Kontrollime parameetri b statistilist olulisust.
Hüpotees H 0: b=0, t b (arvutatud) = ׀b ׀/ m b , m b = S ülejäänud / (δ x  ), kus n on vaatluste arv
), kus n on vaatluste arv
m b = 79,13314895 / (12,57726123  )
= 0,204174979
)
= 0,204174979
t b (arvutatud) = 0,937837482 / 0,204174979 = 4,593302697
t tabel on kriteeriumi maksimaalne võimalik väärtus juhuslike tegurite mõjul antud vabadusastmete (K=n-2) ja olulisuse taseme α (α=0,05) korral. t tabel = 2,2281, kui t (arvutatud) > t tabel, lükatakse hüpotees H 0 tagasi ja tuvastatakse võrrandi parameetrite olulisus.
Meie puhul t b (arvutus) > t tab, seega lükatakse hüpotees H 0 tagasi ja tuvastatakse parameetri a b statistiline olulisus.
Kontrollime parameetri a statistilist olulisust. Hüpotees H 0: a=0 t a (arvutatud) = ׀a ׀/ m a
m a = (S puhkus  )/(n δ x), ma = (79,13314895
)/(n δ x), ma = (79,13314895  )/(12 12,57726123)= 17,89736655, t a (arvutatud) = 54,05926511 / 17,89736655=3,020515055
)/(12 12,57726123)= 17,89736655, t a (arvutatud) = 54,05926511 / 17,89736655=3,020515055
t a (arvutus) > t tab, seega lükatakse hüpotees H 0 tagasi ja tuvastatakse parameetri a statistiline olulisus.
Korrelatsiooni olulisuse hindamine. Kontrollime korrelatsioonikordaja statistilist olulisust.
mrxy=  , mrxy =
, mrxy =  = 0,179320842, trxy = 0,823674909/ 0,179320842 = 4,593302697
= 0,179320842, trxy = 0,823674909/ 0,179320842 = 4,593302697
tr = t b , tr > t tabel, seega tunnistatakse korrelatsioonikordaja statistiline olulisus.
1. Korrelatsioon-regressioonanalüüsi olemus ja selle ülesanded.
2. Regressiooni definitsioon ja selle liigid.
3. Mudeli spetsifikatsiooni omadused. Juhusliku muutuja olemasolu põhjused.
4. Paarisregressiooni valimise meetodid.
5. Vähimruutude meetod.
6. Ühenduse tiheduse ja tugevuse mõõtmise indikaatorid.
7. Statistilise olulisuse hinnangud.
8. Muutuja y prognoositav väärtus ja prognoosi usaldusvahemikud.
1. Korrelatsioon-regressioonanalüüsi olemus ja selle ülesanded. Majandusnähtused, mis on väga mitmekesised, iseloomustavad palju tunnuseid, mis peegeldavad nende protsesside ja nähtuste teatud omadusi ning alluvad vastastikku sõltuvatele muutustele. Mõnel juhul osutub seos tunnuste vahel väga tihedaks (näiteks töötaja tunnitoodang ja tema palk), mõnel juhul aga ei väljendu selline seos üldse või on äärmiselt nõrk (nt. üliõpilaste sugu ja nende õppeedukus). Mida tihedam on nende tunnuste seos, seda täpsemad on tehtud otsused.
Nähtuste ja nende tunnuste vahel on kahte tüüpi sõltuvusi:
funktsionaalne (deterministlik, põhjuslik) sõltuvus . See on antud valemi kujul, mis seob ühe muutuja iga väärtuse teise muutuja rangelt määratletud väärtusega (juhuslike tegurite mõju jäetakse tähelepanuta). Teisisõnu, funktsionaalne sõltuvus on seos, milles sõltumatu muutuja x iga väärtus vastab sõltuva muutuja y täpselt määratletud väärtusele. Majandusteaduses on muutujatevahelised funktsionaalsed seosed üldreegli erandid;
statistiline (stohhastiline, mittedeterministlik) sõltuvus - see on muutujate seos, millele lisandub juhuslike tegurite mõju, s.t. see on seos, milles sõltumatu muutuja x iga väärtus vastab sõltuva muutuja y väärtuste komplektile ja pole ette teada, millise väärtuse y võtab.
Korrelatsioonisõltuvus on statistilise sõltuvuse erijuhtum.
Korrelatsioonisõltuvus - see on seos, milles sõltumatu muutuja x iga väärtus vastab sõltuva muutuja y teatud matemaatilisele ootusele (keskväärtusele).
Korrelatsioonisõltuvus on "mittetäielik" sõltuvus, mis ei ilmne igal üksikjuhul, vaid ainult keskmistes väärtustes piisavalt suure juhtumite arvuga. Näiteks on teada, et töötaja oskuste parandamine toob kaasa tööviljakuse tõusu. See väide leiab praktikas sageli kinnitust, kuid see ei tähenda, et kahel või enamal sama kategooria/taseme töötajal, kes osalevad sarnases protsessis, oleks sama tööviljakus.
Korrelatsioonisõltuvust uuritakse korrelatsiooni- ja regressioonanalüüsi meetoditega.
Korrelatsioon-regressioonanalüüs võimaldab määrata muutujate vahel tiheduse, ühenduse suuna ja selle seose vormi, s.t. selle analüütiline väljendus.
Korrelatsioonianalüüsi põhiülesanne seisneb kahe paarisühendusega märgi ning efektse ja mitme mitmefaktorilise seosega teguri vahelise seose vahelise seose kvantitatiivses määramises ning tuvastatud seose usaldusväärsuse statistilises hindamises.
2. Regressiooni definitsioon ja selle liigid. Regressioonanalüüs on ökonomeetria peamine matemaatiline ja statistiline tööriist. Regressioon suuruse (y) keskmise väärtuse sõltuvust mõnest teisest suurusest või mitmest suurusest on tavaks nimetada (x i).
Sõltuvalt regressioonivõrrandis sisalduvate tegurite arvust on tavaks eristada lihtsat (paaritud) ja mitmikregressiooni.
Lihtne (paaritud) regressioon on mudel, kus sõltuva (seletatava) muutuja y keskväärtust vaadeldakse ühe sõltumatu (selgitava) muutuja x funktsioonina. Paaripõhine regressioon on kaudselt vormi mudel:
Selgelt:
 ,
,
kus a ja b on regressioonikoefitsientide hinnangud.
Mitmekordne regressioon on mudel, kus sõltuva (seletatava) muutuja y keskmist väärtust vaadeldakse mitme sõltumatu (selgitava) muutuja x 1 , x 2 , … x n funktsioonina. Paaripõhine regressioon on kaudselt vormi mudel:
 .
.
Selgelt:
kus a ja b 1 , b 2 , b n on regressioonikoefitsientide hinnangud.
Sellise mudeli näiteks on töötaja palga sõltuvus tema vanusest, haridusest, kvalifikatsioonist, tööstaažist, tööstusest jne.
Sõltuvuse vormi osas on järgmised:
lineaarne regressioon;
mittelineaarne regressioon, mis eeldab mittelineaarsete seoste olemasolu tegurite vahel, mida väljendab vastav mittelineaarne funktsioon. Sageli saab mudelid, mis on välimuselt mittelineaarsed, taandada lineaarseks, mis võimaldab neid liigitada lineaarseteks.
3. Mudeli spetsifikatsiooni omadused. Juhusliku muutuja olemasolu põhjused. Iga ökonomeetriline uuring algab mudeli spetsifikatsioonid , st. mudeli tüübi formuleerimisega, tuginedes muutujatevahelise seose asjakohasele teooriale.
Esiteks tuleb tulemusmärki mõjutavate tegurite kogu hulgast välja tuua kõige olulisemad mõjutegurid. Paaripõhine regressioon on piisav, kui on domineeriv tegur, mida kasutatakse selgitava muutujana. Lihtne regressioonivõrrand iseloomustab kahe muutuja vahelist seost, mis avaldub teatud regulaarsusena vaid keskmiselt kogu vaatluste komplekti puhul. Regressioonivõrrandis on korrelatsioon kujutatud funktsionaalse sõltuvusena, mida väljendab vastav matemaatiline funktsioon. Peaaegu igal üksikul juhul koosneb y väärtus kahest liikmest:
 ,
,
kus y on efektiivse tunnuse tegelik väärtus;
 - regressioonivõrrandi alusel leitud efektiivtunnuse teoreetiline väärtus;
- regressioonivõrrandi alusel leitud efektiivtunnuse teoreetiline väärtus;
 - juhuslik suurus, mis iseloomustab saadud tunnuse reaalväärtuse kõrvalekaldeid regressioonivõrrandiga leitud teoreetilisest väärtusest.
- juhuslik suurus, mis iseloomustab saadud tunnuse reaalväärtuse kõrvalekaldeid regressioonivõrrandiga leitud teoreetilisest väärtusest.
Juhuslik väärtus  nimetatakse ka häireks. See hõlmab mudelis arvestamata tegurite mõju, juhuslikke vigu ja mõõtmisomadusi. Juhusliku muutuja olemasolu mudelis genereerivad kolm allikat:
nimetatakse ka häireks. See hõlmab mudelis arvestamata tegurite mõju, juhuslikke vigu ja mõõtmisomadusi. Juhusliku muutuja olemasolu mudelis genereerivad kolm allikat:
mudeli spetsifikatsioon,
lähteandmete valikulisus,
mõõtmismuutujate omadused.
Spetsifikatsioonivead hõlmavad mitte ainult ühe või teise matemaatilise funktsiooni vale valikut, vaid ka regressioonivõrrandi mis tahes olulise teguri alahindamist (paarregressiooni kasutamine mitmekordse regressiooni asemel).
Koos spetsifikatsioonivigadega võivad esineda valimi võtmise vead, kuna uurija tegeleb tunnuste vaheliste seoste mustrite loomisel kõige sagedamini näidisandmetega. Valimivead tekivad ka esialgse statistilise üldkogumi andmete heterogeensuse tõttu, mis reeglina juhtub majandusprotsesse uurides. Kui populatsioon on heterogeenne, pole regressioonivõrrandil praktilist tähendust. Hea tulemuse saamiseks jäetakse tavaliselt populatsioonist välja uuritud tunnuste ebanormaalsete väärtustega üksused. Ja sel juhul on regressiooni tulemused valimi karakteristikud. Esialgsed andmed
Suurim oht regressioonimeetodite praktilisel kasutamisel on aga mõõtmisvead. Kui spetsifikatsioonivigu saab vähendada mudeli vormi (matemaatilise valemi tüüp) muutmisega, valimi võtmise vigu aga lähteandmete hulga suurendamisega, siis mõõtmisvead nullivad praktiliselt kõik pingutused tunnustevahelise seose kvantifitseerimiseks.
4. Paarisregressiooni valimise meetodid. Eeldusel, et mõõtmisvead on viidud miinimumini, keskenduvad ökonomeetrilised uuringud mudeli spetsifikatsiooni vigadele. Paarregressioonis matemaatilise funktsiooni tüübi valik  saab teha kolmel viisil:
saab teha kolmel viisil:
graafiline;
analüütiline, st. lähtudes uuritava suhte teooriast;
eksperimentaalne.
Kahe tunnuse seose uurimisel graafiline meetod regressioonivõrrandi tüübi valik on üsna selge. See põhineb korrelatsiooniväljal. Seoste kvantifitseerimisel kasutatavad peamised kõverate tüübid










Kahe muutuja vahelise seose kirjeldamiseks mõeldud matemaatiliste funktsioonide klass on üsna lai, kasutatakse ka teist tüüpi kõveraid.
Analüütiline meetod regressioonivõrrandi tüübi valikul lähtutakse uuritavate tunnuste seose materiaalse olemuse uurimisest, aga ka visuaalsest hinnangust seose olemusele. Need. kui me räägime Lafferi kõverast, mis näitab seost maksustamise progressiivsuse ja eelarve tulude vahel, siis me räägime paraboolkõverast ja mikroanalüüsis on isokvandid hüperboolid.