Ko primjenjuje zakone velikih brojeva u životu. Zakon velikih brojeva u Čebiševljevom obliku. Zakon velikih brojeva u Čebiševljevom obliku: sabiranje
Funkcija distribucije slučajna varijabla i njegove osobine.
Funkcija distribucije slučajna varijabla X je funkcija F(X), koja izražava za svaki x vjerovatnoću da će slučajna varijabla X uzeti vrijednost manju od x: F(x)=P(X
Funkcija F(x) ponekad se zove integralna funkcija distribucija ili integralni zakon raspodele.
Svojstva funkcije distribucije:
1. Funkcija distribucije slučajne varijable je nenegativna funkcija između nule i jedan:
0 ≤ F(x) ≤ 1.
2. Funkcija distribucije slučajne varijable je neopadajuća funkcija na cijeloj numeričkoj osi.
3. Na minus beskonačnosti funkcija raspodjele je jednaka nuli, na plus beskonačnosti jednaka je jedan, tj.: F(-∞)= , F(+∞)= .
4. Vjerovatnoća da slučajna varijabla padne u interval [x1,x2) (uključujući x1) jednaka je prirastu njene funkcije distribucije na ovom intervalu, tj. P(x 1 ≤ X< х 2) = F(x 2) - F(x 1).
Nejednakost Markova i Čebiševa
Markova nejednakost
Teorema: Ako slučajna varijabla X uzima samo ne-negativne vrijednosti i ima matematičko očekivanje, tada je za bilo koji pozitivan broj A tačna sljedeća jednakost: P(x>A) ≤ .
Kako su događaji X > A i X ≤ A suprotni, onda zamjenom P(X > A) izražavamo 1 - P(X ≤ A), dolazimo do drugog oblika Markove nejednakosti: P(X ≥ A) ≥1 - .
Markova nejednakost k primjenjuje se na sve nenegativne slučajne varijable.
Čebiševljeva nejednakost
Teorema: Za bilo koju slučajnu varijablu koja ima matematičko očekivanje i varijansu, vrijedi Čebiševljeva nejednakost:
P (|X – a| > ε) ≤ D(X)/ε 2 ili P (|X – a| ≤ ε) ≥ 1 – DX/ε 2, gdje je a= M(X), ε>0.
Zakon veliki brojevi"u obliku" Čebiševljeve teoreme.
Čebiševljeva teorema: Ako varijanse n nezavisne slučajne varijable X1, X2,…. X n ograničeni su na istu konstantu, zatim sa neograničenim povećanjem broja n aritmetička sredina slučajnih varijabli konvergira po vjerovatnoći njihovoj aritmetičkoj sredini matematička očekivanja a 1 , a 2 ...., a n, tj.  .
.
Značenje zakona velikih brojeva je da prosječne vrijednosti slučajnih varijabli teže njihovom matematičkom očekivanju kada n→ ∞ u vjerovatnoći. Odstupanje prosječnih vrijednosti od matematičkog očekivanja postaje proizvoljno malo s vjerovatnoćom bliskom jedinici ako je n dovoljno veliko. Drugim riječima, vjerovatnoća bilo kakvog odstupanja prosječnih vrijednosti od A onoliko mali koliko rasteš n.
30. Bernulijeva teorema.
Bernulijeva teorema: Učestalost događaja u n ponovljena nezavisna ispitivanja, u svakom od kojih se može dogoditi sa istom vjerovatnoćom p, uz neograničeno povećanje broja n konvergiraju po vjerovatnoći sa vjerovatnoćom p ovog događaja u posebnom ispitivanju:  \
\
Bernulijeva teorema je posljedica Čebiševljeve teoreme, jer se učestalost događaja može predstaviti kao aritmetička sredina n nezavisnih alternativnih slučajnih varijabli koje imaju isti zakon raspodjele.
18. Matematičko očekivanje diskretnih i kontinuiranih slučajnih varijabli i njihova svojstva.
Matematičko očekivanje je zbir proizvoda svih njegovih vrijednosti i njihovih odgovarajućih vjerovatnoća
Za diskretnu slučajnu varijablu: 
Za kontinuiranu slučajnu varijablu:
Svojstva matematičkog očekivanja:
1. Matematičko očekivanje konstantne vrijednosti jednako je samoj konstanti: M(S)=C
2. Konstantni faktor se može izvaditi iz predznaka matematičkog očekivanja, tj. M(kX)=kM(X).
3. Matematičko očekivanje algebarskog zbira konačnog broja slučajnih varijabli jednako je istom zbiru njihovih matematičkih očekivanja, tj. M(X±Y)=M(X)±M(Y).
4. Matematičko očekivanje proizvoda konačnog broja nezavisnih slučajnih varijabli jednako je proizvodu njihovih matematičkih očekivanja: M(XY)=M(X)*M(Y).
5. Ako se sve vrijednosti slučajne varijable povećaju (smanje) za konstantu C, tada će se matematičko očekivanje ove slučajne varijable povećati (smanjiti) za istu konstantu C: M(X±C)=M(X)±C.
6. Matematičko očekivanje odstupanja slučajne varijable od njenog matematičkog očekivanja je nula: M=0.
Riječi o velikim brojevima odnose se na broj testova - uzima se u obzir veliki broj vrijednosti slučajne varijable ili kumulativni učinak velikog broja slučajnih varijabli. Suština ovog zakona je sljedeća: iako je nemoguće predvidjeti koju će vrijednost pojedinačna slučajna varijabla uzeti u jednom eksperimentu, međutim, ukupni rezultat djelovanja velikog broja nezavisnih slučajnih varijabli gubi svoju slučajnu prirodu i može biti predvidjeti gotovo pouzdano (tj. sa velikom vjerovatnoćom). Na primjer, nemoguće je predvidjeti na koji način će jedan novčić pasti. Međutim, ako bacite 2 tone novčića, onda s velikim povjerenjem možemo reći da je težina novčića koji su pali s grbom prema gore jednaka 1 toni.
Zakon velikih brojeva se prvenstveno odnosi na takozvanu Čebiševljevu nejednakost, koja procjenjuje u jednom testu vjerovatnoću da slučajna varijabla prihvati vrijednost koja odstupa od prosječne vrijednosti za najviše datu vrijednost.
Čebiševljeva nejednakost. Neka X– proizvoljna slučajna varijabla, a=M(X) , A D(X) – njegovu varijansu. Onda
Primjer. Nominalna (tj. potrebna) vrijednost prečnika čahure okrenute na mašini je jednaka 5mm, a disperzije više nema 0.01 (ovo je tolerancija tačnosti mašine). Procijenite vjerovatnoću da će tokom proizvodnje jedne čaure odstupanje njenog prečnika od nominalnog biti manje od 0.5mm .
Rješenje. Neka r.v. X– prečnik proizvedene čahure. Prema uslovu, njegovo matematičko očekivanje je jednako nominalnom prečniku (ako nema sistematskog kvara u podešavanjima mašine): a=M(X)=5 , i disperzija D(X)≤0,01. Primjenjujući Čebiševljevu nejednakost na ε = 0,5, dobijamo:
Dakle, vjerovatnoća ovakvog odstupanja je prilično velika, te stoga možemo zaključiti da je u jednoj proizvodnji dijela gotovo sigurno da odstupanje prečnika od nominalnog neće premašiti 0.5mm .
U svom značenju, standardna devijacija σ karakteriše prosjek odstupanje slučajne varijable od njenog centra (tj. od njenog matematičkog očekivanja). Jer ovo prosjek odstupanja, tada su tokom testiranja moguća velika (naglasak na o) odstupanja. Koliko su velika odstupanja praktično moguća? Kada smo proučavali normalno raspoređene slučajne varijable, izveli smo pravilo “tri sigma”: normalno raspoređena slučajna varijabla X u jednom testu praktično ne odstupa od svog prosjeka dalje od 3σ, Gdje σ= σ(X)– standardna devijacija r.v. X. Ovo pravilo smo izveli iz činjenice da smo dobili nejednakost
 .
.
Procijenimo sada vjerovatnoću za proizvoljno slučajna varijabla X prihvati vrijednost koja se razlikuje od prosjeka za najviše tri puta standardnu devijaciju. Primjenjujući Čebiševljevu nejednakost na ε = 3σ i s obzirom na to D(H)= σ 2 , dobijamo:
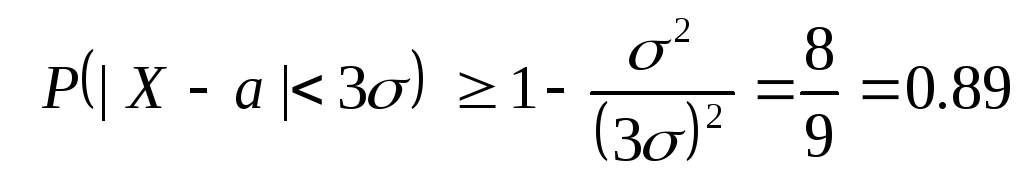 .
.
dakle, Uglavnom možemo procijeniti vjerovatnoću slučajne varijable koja odstupa od srednje vrijednosti za najviše tri standardne devijacije po broju 0.89 , dok se za normalnu distribuciju to može garantovati sa vjerovatnoćom 0.997 .
Čebiševljeva nejednakost se može generalizirati na sistem nezavisnih identično distribuiranih slučajnih varijabli.
Generalizirana Čebiševljeva nejednakost. Ako su nezavisne slučajne varijable X 1 , X 2 , … , X n M(X i )= a i varijanse D(X i )= D, To
At n=1 ova nejednakost se transformiše u nejednakost Čebiševa koja je gore formulisana.
Čebiševljeva nejednakost, koja ima nezavisan značaj za rješavanje odgovarajućih problema, koristi se za dokazivanje takozvane Čebiševljeve teoreme. Prvo ćemo govoriti o suštini ove teoreme, a zatim dati njenu formalnu formulaciju.
Neka X 1
, X 2
, … , X n– veliki broj nezavisnih slučajnih varijabli sa matematičkim očekivanjima M(X 1
)=a 1
, … , M(X n )=a n. Iako svaki od njih, kao rezultat eksperimenta, može uzeti vrijednost daleko od svog prosjeka (tj. matematičkog očekivanja), međutim, slučajna varijabla  , jednak njihovoj aritmetičkoj sredini, najvjerovatnije će poprimiti vrijednost blisku fiksnom broju
, jednak njihovoj aritmetičkoj sredini, najvjerovatnije će poprimiti vrijednost blisku fiksnom broju  (ovo je prosjek svih matematičkih očekivanja). To znači sljedeće. Neka, kao rezultat testa, nezavisne slučajne varijable X 1
, X 2
, … , X n(ima ih mnogo!) uzimali su vrijednosti u skladu s tim X 1
, X 2
, … , X n respektivno. Zatim, ako se te vrijednosti mogu pokazati da su daleko od prosječnih vrijednosti odgovarajućih slučajnih varijabli, njihova prosječna vrijednost
(ovo je prosjek svih matematičkih očekivanja). To znači sljedeće. Neka, kao rezultat testa, nezavisne slučajne varijable X 1
, X 2
, … , X n(ima ih mnogo!) uzimali su vrijednosti u skladu s tim X 1
, X 2
, … , X n respektivno. Zatim, ako se te vrijednosti mogu pokazati da su daleko od prosječnih vrijednosti odgovarajućih slučajnih varijabli, njihova prosječna vrijednost  će najvjerovatnije biti blizu tog broja
će najvjerovatnije biti blizu tog broja  . Dakle, aritmetička sredina velikog broja slučajnih varijabli već gubi svoj slučajni karakter i može se predvidjeti s velikom preciznošću. Ovo se može objasniti činjenicom da su slučajna odstupanja vrijednosti X i od a i mogu biti različitih predznaka, pa se stoga ukupno ova odstupanja najvjerovatnije nadoknađuju.
. Dakle, aritmetička sredina velikog broja slučajnih varijabli već gubi svoj slučajni karakter i može se predvidjeti s velikom preciznošću. Ovo se može objasniti činjenicom da su slučajna odstupanja vrijednosti X i od a i mogu biti različitih predznaka, pa se stoga ukupno ova odstupanja najvjerovatnije nadoknađuju.
Terema Chebyshev (zakon velikih brojeva u obliku Čebiševa). Neka X 1 , X 2 , … , X n … – niz parno nezavisnih slučajnih varijabli čije su varijanse ograničene na isti broj. Tada, bez obzira koliko mali broj ε uzmemo, vjerovatnoća nejednakosti
će biti što bliži jedinici ako je broj n uzeti dovoljno velike slučajne varijable. Formalno, to znači da pod uslovima teoreme
Ova vrsta konvergencije naziva se konvergencija po vjerovatnoći i označava se:
Dakle, Čebiševljev teorem kaže da ako postoji dovoljno veliki broj nezavisnih slučajnih varijabli, onda će njihova aritmetička sredina u jednom testu gotovo pouzdano poprimiti vrijednost blisku srednjoj vrijednosti njihovih matematičkih očekivanja.
Najčešće se Čebiševljeva teorema primjenjuje u situacijama kada su slučajne varijable X 1 , X 2 , … , X n … imaju istu distribuciju (tj. isti zakon raspodjele ili istu gustinu vjerovatnoće). U stvari, to je jednostavno veliki broj instanci iste slučajne varijable.
Posljedica(generalizovana Čebiševljeva nejednakost). Ako su nezavisne slučajne varijable X 1 , X 2 , … , X n … imaju istu distribuciju sa matematičkim očekivanjima M(X i )= a i varijanse D(X i )= D, To
 , tj.
, tj.  .
.
Dokaz slijedi iz generalizirane Čebiševe nejednakosti prelaskom na granicu na n→∞ .
Napominjemo još jednom da gore napisane jednakosti ne garantuju vrijednost količine  teži za A at n→∞. Ova količina i dalje ostaje slučajna varijabla, a njene pojedinačne vrijednosti mogu biti prilično daleko A. Ali vjerovatnoća takvog (daleko od toga A) vrijednosti sa povećanjem n teži 0.
teži za A at n→∞. Ova količina i dalje ostaje slučajna varijabla, a njene pojedinačne vrijednosti mogu biti prilično daleko A. Ali vjerovatnoća takvog (daleko od toga A) vrijednosti sa povećanjem n teži 0.
Komentar. Zaključak posljedice očito vrijedi i u opštijem slučaju, kada su nezavisne slučajne varijable X 1 , X 2 , … , X n … imaju različite distribucije, ali ista matematička očekivanja (jednako A) i zajednički ograničene varijacije. To nam omogućava da predvidimo tačnost mjerenja određene veličine, čak i ako su ta mjerenja vršena različitim instrumentima.
Razmotrimo detaljnije primjenu ove posljedice pri mjerenju veličina. Hajde da koristimo neki uređaj n mjerenja iste veličine, čija je prava vrijednost jednaka A a mi ne znamo. Rezultati takvih mjerenja X 1
, X 2
, … , X n mogu se značajno razlikovati jedni od drugih (i od prave vrijednosti A) zbog različitih nasumičnih faktora (promjene pritiska, temperature, nasumične vibracije, itd.). Uzmite u obzir r.v. X– očitavanje instrumenta za jedno mjerenje veličine, kao i skup r.v. X 1
, X 2
, … , X n– očitavanje instrumenta pri prvom, drugom, ..., posljednjem mjerenju. Dakle, svaka od veličina X 1
, X 2
, … , X n
postoji samo jedna od instanci s.v. X, te stoga svi imaju istu distribuciju kao r.v. X. Kako rezultati mjerenja ne zavise jedan od drugog, onda r.v. X 1
, X 2
, … , X n može se smatrati nezavisnim. Ako uređaj ne proizvodi sistematsku grešku (na primjer, nula na skali nije "isključena", opruga nije rastegnuta itd.), tada možemo pretpostaviti da je matematičko očekivanje M(X) = a, i zbog toga M(X 1
) = ... = M(X n ) = a. Dakle, ispunjeni su uslovi gornjeg korolarca, te stoga, kao približna vrijednost količine A možemo uzeti “realizaciju” slučajne varijable  u našem eksperimentu (koji se sastoji od provođenja serije n mjerenja), tj.
u našem eksperimentu (koji se sastoji od provođenja serije n mjerenja), tj.
 .
.
At veliki broj mjerenja, dobra tačnost proračuna pomoću ove formule je praktično pouzdana. Ovo je obrazloženje praktičnog principa da se kod velikog broja mjerenja njihova aritmetička sredina praktično ne razlikuje mnogo od prave vrijednosti izmjerene vrijednosti.
Metoda "uzorkovanja", koja se široko koristi u matematičkoj statistici, temelji se na zakonu velikih brojeva, koji omogućava da se njegove objektivne karakteristike dobiju s prihvatljivom točnošću iz relativno malog uzorka vrijednosti slučajne varijable. Ali o tome će biti riječi u sljedećem odjeljku.
Primjer. Određena količina se mjeri na mjernom uređaju koji ne pravi sistematska izobličenja A jednom (primljena vrijednost X 1
), a zatim još 99 puta (dobivene vrijednosti X 2
, … , X 100
). Za pravu mjernu vrijednost A prvo se uzima rezultat prvog mjerenja  , a zatim aritmetičku sredinu svih mjerenja
, a zatim aritmetičku sredinu svih mjerenja  . Tačnost mjerenja uređaja je takva da standardna devijacija mjerenja σ nije veća od 1 (dakle, varijansa D=σ
2
takođe ne prelazi 1). Za svaku metodu merenja procenite verovatnoću da greška merenja neće preći 2.
. Tačnost mjerenja uređaja je takva da standardna devijacija mjerenja σ nije veća od 1 (dakle, varijansa D=σ
2
takođe ne prelazi 1). Za svaku metodu merenja procenite verovatnoću da greška merenja neće preći 2.
Rješenje. Neka r.v. X– očitavanje instrumenta za jedno mjerenje. Onda po uslovu M(X)=a. Da bismo odgovorili na postavljena pitanja, primjenjujemo generaliziranu Čebiševljevu nejednakost

na ε =2
prvo za n=1
a zatim za n=100
. U prvom slučaju dobijamo  , au drugom. Dakle, drugi slučaj praktično garantuje zadatu tačnost merenja, dok prvi ostavlja velike sumnje u tom smislu.
, au drugom. Dakle, drugi slučaj praktično garantuje zadatu tačnost merenja, dok prvi ostavlja velike sumnje u tom smislu.
Primijenimo gornje tvrdnje na slučajne varijable koje nastaju u Bernoullijevoj shemi. Prisjetimo se suštine ove sheme. Neka se proizvede n nezavisna ispitivanja, od kojih svaki sadrži neki događaj A može se pojaviti sa istom vjerovatnoćom R, A q=1–r(u smislu, ovo je vjerovatnoća suprotnog događaja - da se događaj ne dogodi A) . Hajde da potrošimo neki broj n takvi testovi. Razmotrimo slučajne varijable: X 1 – broj pojavljivanja događaja A V 1 -ti test, ..., X n– broj pojavljivanja događaja A V n-th test. Svi upisani s.v. može poprimiti vrijednosti 0 ili 1 (događaj A može ili ne mora da se pojavi u testu) i vrednost 1 u skladu sa uslovom se prihvata u svakom ogledu sa verovatnoćom str(vjerovatnoća nastanka događaja A u svakom ispitivanju) i vrijednost 0 sa vjerovatnoćom q= 1 – str. Dakle, ove veličine imaju iste zakone raspodjele:
|
X 1 | ||
|
X n | ||
Stoga su prosječne vrijednosti ovih veličina i njihove varijanse također iste: M(X 1 )=0 ∙ q+1 ∙ p= p, …, M(X n )= str ; D(X 1 )=(0 2 ∙ q+1 2 ∙ str)− str 2 = str∙(1− str)= str ∙ q, … , D(X n )= str ∙ q. Zamjenom ovih vrijednosti u generaliziranu Čebiševljevu nejednakost, dobivamo
 .
.
Jasno je da je r.v. X=X 1 +…+X n je broj pojavljivanja događaja A u svemu n testovi (kako kažu - "broj uspjeha" u n testovi). Neka u provode n događaj testiranja A pojavio se u k Od njih. Tada se prethodna nejednakost može zapisati kao
 .
.
Ali veličina  , jednak omjeru broja pojavljivanja događaja A V n nezavisnih ispitivanja, prema ukupnom broju ispitivanja, ranije se nazivala relativna učestalost događaja A V n testovi. Stoga postoji nejednakost
, jednak omjeru broja pojavljivanja događaja A V n nezavisnih ispitivanja, prema ukupnom broju ispitivanja, ranije se nazivala relativna učestalost događaja A V n testovi. Stoga postoji nejednakost
 .
.
Prelazimo sada na granicu na n→∞, dobijamo  , tj.
, tj.  (po vjerovatnoći). Ovo predstavlja sadržaj zakona velikih brojeva u Bernoullijevom obliku. Iz ovoga proizilazi da sa dovoljno velikim brojem testova n proizvoljno mala odstupanja relativne frekvencije
(po vjerovatnoći). Ovo predstavlja sadržaj zakona velikih brojeva u Bernoullijevom obliku. Iz ovoga proizilazi da sa dovoljno velikim brojem testova n proizvoljno mala odstupanja relativne frekvencije  događaje iz njegove vjerovatnoće R- gotovo pouzdani događaji, a velika odstupanja - gotovo nemoguća. Iz toga proizlazi zaključak o takvoj stabilnosti relativnih frekvencija (o kojoj smo ranije govorili kao eksperimentalničinjenica) opravdava prethodno uvedenu statističku definiciju vjerovatnoće događaja kao broja oko kojeg relativna učestalost događaja fluktuira.
događaje iz njegove vjerovatnoće R- gotovo pouzdani događaji, a velika odstupanja - gotovo nemoguća. Iz toga proizlazi zaključak o takvoj stabilnosti relativnih frekvencija (o kojoj smo ranije govorili kao eksperimentalničinjenica) opravdava prethodno uvedenu statističku definiciju vjerovatnoće događaja kao broja oko kojeg relativna učestalost događaja fluktuira.
S obzirom da je izraz str∙
q=
str∙(1−
str)=
str−
str 2
ne prelazi interval izmene  (ovo je lako provjeriti pronalaženjem minimuma ove funkcije na ovom segmentu), iz gornje nejednakosti
(ovo je lako provjeriti pronalaženjem minimuma ove funkcije na ovom segmentu), iz gornje nejednakosti  lako to dobiti
lako to dobiti
 ,
,
koji se koristi u rješavanju relevantnih problema (jedan od njih će biti dat u nastavku).
Primjer. Novčić je bačen 1000 puta. Procijenite vjerovatnoću da će odstupanje relativne učestalosti pojavljivanja grba od njegove vjerovatnoće biti manje od 0,1.
Rješenje. Primjena nejednakosti  at str=
q=1/2
,
n=1000
,
ε=0,1, primićemo .
at str=
q=1/2
,
n=1000
,
ε=0,1, primićemo .
Primjer. Procijenite vjerovatnoću da, pod uslovima iz prethodnog primjera, broj k ispušteni amblemi će biti u rasponu od 400 prije 600 .
Rješenje. Stanje 400<
k<600
znači da 400/1000<
k/
n<600/1000
, tj. 0.4<
W n (A)<0.6
ili  . Kao što smo upravo vidjeli iz prethodnog primjera, vjerovatnoća takvog događaja nije ništa manja 0.975
.
. Kao što smo upravo vidjeli iz prethodnog primjera, vjerovatnoća takvog događaja nije ništa manja 0.975
.
Primjer. Za izračunavanje vjerovatnoće nekog događaja A Provedeno je 1000 eksperimenata u kojima je događaj A pojavio 300 puta. Procijenite vjerovatnoću da je relativna frekvencija (jednaka 300/1000 = 0,3) udaljena od prave vjerovatnoće R ne više od 0,1.
Rješenje. Primjenjujući gornju nejednakost  za n=1000, ε=0.1, dobijamo .
za n=1000, ε=0.1, dobijamo .
Praksa proučavanja slučajnih pojava pokazuje da, iako se rezultati pojedinačnih posmatranja, čak i onih sprovedenih pod istim uslovima, mogu znatno razlikovati, u isto vreme, prosečni rezultati za dovoljno veliki broj posmatranja su stabilni i slabo zavise od rezultati pojedinačnih zapažanja.
Teorijska osnova za ovo izvanredno svojstvo slučajnih pojava je zakon velikih brojeva. Naziv “zakon velikih brojeva” kombinuje grupu teorema koje utvrđuju stabilnost prosječnih rezultata velikog broja slučajnih pojava i objašnjavaju razlog za tu stabilnost.
Najjednostavniji oblik zakona velikih brojeva i istorijski prva teorema ovog odjeljka je Bernulijeva teorema, koji kaže da ako je vjerovatnoća događaja ista u svim pokušajima, onda kako se broj pokušaja povećava, učestalost događaja teži vjerovatnoći događaja i prestaje biti slučajna.
Poissonova teorema kaže da učestalost događaja u nizu nezavisnih pokušaja teži aritmetičkoj sredini njegovih vjerovatnoća i prestaje biti slučajna.
Granične teoreme teorije vjerovatnoće, teoreme Moivre-Laplace objasni prirodu stabilnosti učestalosti pojavljivanja događaja. Ova priroda leži u činjenici da je granična distribucija broja pojavljivanja događaja uz neograničeno povećanje broja pokušaja (ako je vjerovatnoća događaja ista u svim pokušajima) normalna distribucija.
Centralna granična teorema objašnjava rasprostranjenost normalan zakon distribucije. Teorema kaže da kad god se slučajna varijabla formira kao rezultat dodavanja velikog broja nezavisnih slučajnih varijabli sa konačnim varijacijama, zakon distribucije ove slučajne varijable ispada praktički normalno po zakonu.
Teorema data ispod pod naslovom " Zakon velikih brojeva“ navodi da pod određenim, prilično opštim uslovima, sa povećanjem broja slučajnih varijabli, njihova aritmetička sredina teži aritmetičkoj sredini matematičkih očekivanja i prestaje da bude slučajna.
Ljapunovljev teorem objašnjava rasprostranjenost normalan zakon distribucije i objašnjava mehanizam njenog nastanka. Teorema nam omogućava da kažemo da kad god se slučajna varijabla formira kao rezultat sabiranja velikog broja nezavisnih slučajnih varijabli, čije su varijanse male u odnosu na varijansu zbira, zakon distribucije ove slučajne varijable se mijenja. praktično normalno po zakonu. A budući da su slučajne varijable uvijek generirane beskonačnim brojem uzroka i najčešće nijedan od njih nema disperziju uporedivu sa disperzijom same slučajne varijable, većina slučajnih varijabli koje se susreću u praksi podliježu normalnom zakonu distribucije.
Na osnovu kvalitativnih i kvantitativnih iskaza zakona velikih brojeva Nejednakost Čebiševa. Određuje gornju granicu vjerovatnoće da je odstupanje vrijednosti slučajne varijable od njenog matematičkog očekivanja veće od određenog specificiranog broja. Izvanredno je da Čebiševljeva nejednakost daje procjenu vjerovatnoće nekog događaja za slučajnu varijablu čija je distribucija nepoznata, poznati su samo njeno matematičko očekivanje i varijansa.
Čebiševljeva nejednakost. Ako slučajna varijabla x ima varijansu, tada za bilo koje e > 0 vrijedi sljedeća nejednakost: ![]() , Gdje M x i D x - matematičko očekivanje i varijansa slučajne varijable x.
, Gdje M x i D x - matematičko očekivanje i varijansa slučajne varijable x.
Bernulijeva teorema. Neka je m n broj uspjeha u n Bernoullijevih pokušaja, a p vjerovatnoća uspjeha u pojedinačnom pokušaju. Tada je za bilo koje e > 0 tačno ![]() .
.
Centralna granična teorema. Ako su slučajne varijable x 1 , x 2 , …, x n , … nezavisne po paru, identično raspoređene i imaju konačnu varijansu, tada za n ® ravnomjerno po x (- ,)
Ako je fenomen stabilnosti prosjek se dešava u stvarnosti, a zatim u matematički model, uz pomoć kojih proučavamo slučajne pojave, mora postojati teorema koja odražava ovu činjenicu.
Pod uslovima ove teoreme uvodimo ograničenja na slučajne varijable X 1 , X 2 , …, X n:
a) svaka slučajna varijabla X i ima matematička očekivanja
M(X i) = a;
b) varijansa svake slučajne varijable je konačna ili, možemo reći da su varijanse odozgo ograničene istim brojem, npr. WITH, tj.
D(X i) < C, i = 1, 2, …, n;
c) slučajne varijable su nezavisne u paru, odnosno bilo koje dvije X i I X j at i¹ j nezavisni.
Onda očigledno
D(X 1 + X 2 + … + X n)=D(X 1) +D(X 2) + ... + D(X n).
Formulirajmo zakon velikih brojeva u obliku Čebiševa.
Čebiševljeva teorema: uz neograničeno povećanje broja n nezavisni testovi" aritmetička sredina posmatranih vrijednosti slučajne varijable konvergira po vjerovatnoći njenom matematičkom očekivanju “, odnosno za svaku pozitivu ε
R(| –a| < ε ) = 1. (4.1.1)
Značenje izraza "aritmetička sredina = konvergira vjerovatnoćom u a" da li je to verovatnoća da će se što manje razlikovati od a, približava se 1 bez ograničenja kako se broj povećava n.
Dokaz. Za konačan broj n nezavisnim testovima, primjenjujemo Čebiševljevu nejednakost za slučajnu varijablu = :
R(|– M()| < ε ) ≥ 1 – . (4.1.2)
Uzimajući u obzir ograničenja a – b, izračunavamo M( ) I D( ):
M( ) = = = = = = A;
D( ) = = = = = = .
Zamena M( ) I D( ) u nejednakost (4.1.2), dobijamo
R(| –a| < ε )≥1 – .
Ako u nejednakosti (4.1.2) uzmemo proizvoljno malu ε >0i n® ¥, onda dobijamo
što dokazuje Čebiševljevu teoremu.
Iz razmatrane teoreme slijedi važan praktični zaključak: imamo pravo zamijeniti nepoznatu vrijednost matematičkog očekivanja slučajne varijable srednjom aritmetičkom vrijednošću dobivenom iz dovoljno velikog broja eksperimenata. Štoviše, što više eksperimenata ima za izračunavanje, vjerovatnije (pouzdanije) se može očekivati da će greška povezana s ovom zamjenom ( - A) neće premašiti navedenu vrijednost ε .
Osim toga, možete riješiti i druge praktične probleme. Na primjer, prema vrijednostima vjerovatnoće (pouzdanosti). R=R(| – a|< ε ) i maksimalna dozvoljena greška ε odrediti potreban broj eksperimenata n; By R I P definisati ε; By ε I P odrediti granicu vjerovatnoće nekog događaja | – a |< ε.
Poseban slučaj. Neka u n uočeni testovi n vrijednosti slučajne varijable X, imajući matematička očekivanja M(X) i varijansu D(X). Dobijene vrijednosti se mogu smatrati slučajnim varijablama X 1 ,X 2 ,X 3 , ... ,Xn,. Ovo treba shvatiti na sljedeći način: niz P testovi se provode više puta, pa kao rezultat i-th test i= l, 2, 3, ..., P, u svakoj seriji testova pojavit će se jedna ili druga vrijednost slučajne varijable X, nije poznato unaprijed. dakle, i-e vrijednost x i slučajna varijabla dobijena u i-ti test, mijenja se nasumično ako prelazite s jedne serije testova na drugu. Dakle, svaka vrijednost x i može se smatrati slučajnom varijablom Xi.
Pretpostavimo da testovi zadovoljavaju sljedeće zahtjeve:
1. Testovi su nezavisni. To znači da su rezultati X 1 , X 2 ,
X 3 , ..., Xn testovi – nezavisne slučajne varijable.
2. Testovi se izvode pod istim uslovima - to znači, sa stanovišta teorije verovatnoće, da svaka od slučajnih varijabli X 1 ,X 2 ,X 3 , ... ,Xn ima isti zakon raspodjele kao i originalna vrijednost X, Zbog toga M(X i) = M(X)I D(X i) = D(X), i = 1, 2, .... P.
Uzimajući u obzir gore navedene uslove, dobijamo
R(| –a| < ε )≥1 – . (4.1.3)
Primjer 4.1.1. X je jednako 4. Koliko je nezavisnih eksperimenata potrebno da bi se, sa vjerovatnoćom od najmanje 0,9, moglo očekivati da će se aritmetička srednja vrijednost ove slučajne varijable razlikovati od matematičkog očekivanja za manje od 0,5?
Rješenje.Prema uslovima problema ε = 0,5; R(| – a|< 0,5) ≥ 0.9. Primjena formule (4.1.3) za slučajnu varijablu X, dobijamo
P(|– M(X)| < ε ) ≥ 1 – .
Iz odnosa
1 – = 0,9
hajde da definišemo
P= = = 160.
Odgovori: Potrebno je 160 nezavisnih eksperimenata.
Ako pretpostavimo da je aritmetička sredina se normalno distribuira, dobijamo:
R(| – a|< ε )= 2Φ () ≥ 0,9.
Odakle, koristeći tabelu Laplaceove funkcije, dobijamo ≥
≥
1,645, odnosno ≥ 6,58, tj. n ≥49.
Primjer 4.1.2. Varijanca slučajne varijable X jednako D( X) = 5. Izvedeno je 100 nezavisnih eksperimenata iz kojih je izračunato . Umjesto nepoznate vrijednosti matematičkog očekivanja A prihvaćeno . Odredite maksimalnu dozvoljenu vrijednost greške s vjerovatnoćom od najmanje 0,8.
Rješenje. Prema uslovima problema n= 100, R(| –a|< ε ) ≥0,8. Primijenimo formulu (4.1.3)
R(| –a|< ε ) ≥1 – .
Iz odnosa
1 – = 0,8
hajde da definišemo ε :
ε 2 = = = 0,25.
dakle, ε = 0,5.
Odgovori: maksimalna vrijednost greške ε = 0,5.
4.2. Zakon velikih brojeva u Bernoullijevom obliku
Iako je osnova svih statističkih zaključaka koncept vjerovatnoće, postoji samo nekoliko slučajeva u kojima možemo direktno odrediti vjerovatnoću događaja. Ponekad se ova vjerovatnoća može utvrditi na osnovu razmatranja simetrije, jednakih mogućnosti, itd., ali ne postoji univerzalna metoda koja bi omogućila da se ukaže na njenu vjerovatnoću za proizvoljan događaj. Bernulijeva teorema omogućava aproksimaciju vjerovatnoće ako za događaj koji nas zanima A mogu se izvršiti ponovljeni nezavisni testovi. Neka se proizvede P nezavisna ispitivanja, u svakom od kojih je vjerovatnoća nastanka nekog događaja A je konstantan i jednak R.
Bernulijeva teorema. Uz neograničeno povećanje broja nezavisnih testova P relativna učestalost pojavljivanja događaja A konvergira vjerovatnoća prema vjerovatnoći str pojava događaja A,T. e.
P(½ - str½≤ ε) = 1, (4.2.1)
Gdje ε – proizvoljno mali pozitivan broj.
Za finale n pod uslovom da će Čebiševljeva nejednakost za slučajnu varijablu imati oblik:
P(| – p|< ε ) ≥ 1 – .(4.2.2)
Dokaz. Primijenimo Čebiševljevu teoremu. Neka X i– broj pojavljivanja događaja A V i-ti test, i= 1, 2, . . . , n. Svaka od količina X i može uzeti samo dvije vrijednosti:
X i= 1 (događaj A dogodilo) sa vjerovatnoćom str,
X i= 0 (događaj A nije došlo) sa vjerovatnoćom q= 1–str.
Neka Yn= . Suma X 1 + X 2 + … + X n jednak broju m pojave događaja A V n testovi (0 m n), što znači Yn= – relativna učestalost pojavljivanja događaja A V n testovi. Očekivanja i varijanse X i jednaki su redom:
M( ) = 1∙str + 0∙q = str,
Primjer 4.2.1. Kako bi se utvrdio postotak grešaka proizvoda, 1000 jedinica je provjereno pomoću šeme uzorkovanja povrata. Kolika je vjerovatnoća da će se udio nedostataka utvrđen ovim uzorkom u apsolutnoj vrijednosti od udjela nedostataka za cijelu seriju razlikovati za najviše 0,01, ako se zna da u prosjeku na svakih 10.000 proizvoda dolazi 500 neispravnih?
Rješenje. Prema problemskim uslovima, broj nezavisnih ispitivanja n= 1000;
str= = 0,05; q= 1 – str= 0,95; ε = 0,01.
Primjenom formule (4.2.2) dobijamo
P(| –p|< 0,01) ≥ 1 – = 1 – = 0,527.
Odgovori: sa vjerovatnoćom od najmanje 0,527, možemo očekivati da će se udio nedostataka u uzorku (relativna učestalost defekata) razlikovati od udjela nedostataka u svim proizvodima (vjerovatnoća defekata) za najviše 0,01.
Primjer 4.2.2. Prilikom štancanja dijelova vjerovatnoća oštećenja je 0,05. Koliko dijelova treba provjeriti da bi se, s vjerovatnoćom od najmanje 0,95, moglo očekivati da će se relativna učestalost neispravnih proizvoda razlikovati od vjerovatnoće neispravnih proizvoda za manje od 0,01?
Rješenje. Prema uslovima problema R= 0,05; q= 0,95; ε = 0,01;
P(| – p|<0,01) ≥ 0,95.
Iz jednakosti 1 – = nalazimo 0,95 n:
n= = =9500.
Odgovori: 9500 dijelova treba provjeriti.
Komentar. Procene potrebnog broja zapažanja dobijenih primenom Bernulijeve (ili Čebiševe) teoreme su veoma preuveličane. Postoje preciznije procjene koje su predložili Bernstein i Khinchin, ali one zahtijevaju složeniji matematički aparat. Kako bi se izbjeglo preuveličavanje procjena, ponekad se koristi Laplaceova formula
P(| – p|< ε ) ≈ 2Φ .
Nedostatak ove formule je nedostatak procjene dozvoljene greške.
Fenomen stabilizacije učestalosti pojavljivanja slučajnih događaja, otkriven na velikom i raznovrsnom materijalu, u početku nije imao nikakvo opravdanje i doživljavan je kao čisto empirijska činjenica. Prvi teorijski rezultat u ovoj oblasti bila je poznata Bernoullijeva teorema, objavljena 1713. godine, koja je postavila temelje za zakone velikih brojeva.
Bernulijeva teorema po svom sadržaju je granična teorema, tj. izjava asimptotičkog značenja koja govori šta će se dogoditi sa probabilističkim parametrima uz veliki broj zapažanja. Rodonačelnik svih modernih brojnih izjava ovog tipa je upravo Bernoullijev teorem.
Danas se čini da je matematički zakon velikih brojeva odraz nekog opšteg svojstva mnogih realnih procesa.
Imajući želju da zakonu velikih brojeva da najveći mogući obim, koji odgovara daleko od iscrpljenih potencijalnih mogućnosti primene ovog zakona, jedan od najvećih matematičara našeg veka A. N. Kolmogorov formulisao je njegovu suštinu na sledeći način: zakon velikih brojeva je „opšti princip na osnovu kojeg ukupno djelovanje velikog broja slučajnih faktora dovodi do rezultata gotovo neovisnog o slučaju.”
Dakle, zakon velikih brojeva ima dva tumačenja. Jedan je matematički, povezan sa specifičnim matematičkim modelima, formulacijama, teorijama, a drugi je opštiji, koji prevazilazi ovaj okvir. Drugo tumačenje povezano je s fenomenom formiranja manje ili više usmjerenog djelovanja, koji se često uočava u praksi, na pozadini velikog broja skrivenih ili vidljivih faktora djelovanja koji izvana nemaju takav kontinuitet. Primjeri povezani s drugim tumačenjem su određivanje cijena na slobodnom tržištu i formiranje javnog mnijenja o određenom pitanju.
Uočivši ovo opšte tumačenje zakona velikih brojeva, okrenimo se konkretnim matematičkim formulacijama ovog zakona.
Kao što smo već rekli, prvi i fundamentalno najvažniji za teoriju vjerovatnoće je Bernoullijev teorem. Sadržaj ove matematičke činjenice, koja odražava jedan od najvažnijih zakona okolnog svijeta, svodi se na sljedeće.
Razmotrite niz nepovezanih (tj. nezavisnih) testova, čiji se uslovi dosljedno reproduciraju od testa do testa. Rezultat svakog testa je pojava ili nepostojanje događaja koji nas zanima A.
Ovaj postupak (Bernoullijeva šema) se očito može smatrati tipičnim za mnoga praktična područja: „dečak – devojčica“ u redosledu novorođenčadi, dnevna meteorološka posmatranja („kiša je padala – nije“), kontrola toka proizvedenih proizvoda ( „normalan – neispravan“) itd.
Učestalost pojavljivanja događaja A at P testovi ( t A -
učestalost događaja A V P testovi) ima sa rastom P tendencija stabilizacije njegove vrijednosti je empirijska činjenica.
Bernulijeva teorema. Odaberimo bilo koji proizvoljno mali pozitivan broj e. Tada
Naglašavamo da matematičku činjenicu koju je Bernoulli utvrdio u određenom matematičkom modelu (u Bernoullijevoj šemi) ne treba miješati sa empirijski utvrđenom pravilnošću stabilnosti frekvencije. Bernuli se nije zadovoljio samo navođenjem formule (9.1), već je, uzimajući u obzir potrebe prakse, dao ocjenu nejednakosti prisutne u ovoj formuli. U nastavku ćemo se osvrnuti na ovo tumačenje.
Bernulijev zakon velikih brojeva bio je predmet istraživanja velikog broja matematičara koji su nastojali da ga preciziraju. Jedno od ovih poboljšanja dobio je engleski matematičar Moivre i trenutno se zove Moivre-Laplaceova teorema. U Bernoullijevoj shemi, razmotrite slijed normaliziranih veličina:
Integralni teorem Moivre - Laplace. Odaberimo bilo koja dva broja X ( I x 2. U ovom slučaju x, x 7, zatim at P -» °°
Ako je na desnoj strani formule (9.3) varijabla x x teže beskonačnosti, tada će rezultirajuća granica, ovisno samo o x 2 (indeks 2 se u ovom slučaju može ukloniti), biti funkcija distribucije, naziva se standardna normalna distribucija, ili Gaussov zakon.
Desna strana formule (9.3) jednaka je y = F(x 2) - F(x x). F(x 2)-> 1 at x 2-> °° i F(x,) -> 0 na x, -> Zbog izbora dovoljno velikog
X] > 0 i X]n je dovoljno velik po apsolutnoj vrijednosti, dobijamo sljedeću nejednakost:
Uzimajući u obzir formulu (9.2), možemo izdvojiti praktično pouzdane procjene:
Ako se nivo pouzdanosti od y = 0,95 (tj. vjerovatnoća greške od 0,05) nekome čini nedovoljnim, možete "igrati na sigurno" i konstruirati malo širi interval povjerenja koristeći gore navedeno pravilo tri sigma:
Ovaj interval veoma odgovara visoki nivo povjerenje y = 0,997 (vidi tabele normalne distribucije).
Razmotrimo primjer koji uključuje bacanje novčića. Hajde da bacimo novčić n = 100 puta. Može li se dogoditi da frekvencija Rće se veoma razlikovati od vjerovatnoće R= 0,5 (pod pretpostavkom da je novčić simetričan), na primjer, hoće li biti jednak nuli? Da biste to učinili, potrebno je da grb ne ispadne ni jednom. Takav događaj je teoretski moguć, ali smo već izračunali slične vjerovatnoće; za ovaj događaj će biti jednaka  Ova vrijednost
Ova vrijednost
izuzetno mali, njegov red je broj sa 30 nula iza decimalnog zareza. Događaj s takvom vjerovatnoćom može se sa sigurnošću smatrati praktično nemogućim. Koja su odstupanja frekvencije od vjerovatnoće praktično moguća sa velikim brojem eksperimenata? Koristeći Moivre-Laplaceovu teoremu, na ovo pitanje odgovaramo na sljedeći način: sa vjerovatnoćom at= 0,95 frekvencija grba R uklapa se u interval pouzdanosti:
Ako se čini da greška od 0,05 nije mala, potrebno je povećati broj eksperimenata (bacanja novčića). Prilikom povećanja Pširina intervala povjerenja se smanjuje (nažalost, ne tako brzo koliko bismo željeli, već obrnuto proporcionalno -Jn). Na primjer, kada P= 10.000 dobijamo to R leži u intervalu poverenja sa verovatnoćom poverenja at= 0,95: 0,5 ±0,01.
Dakle, kvantitativno smo razumjeli pitanje aproksimacije frekvencije vjerovatnoći.
Sada pronađimo vjerovatnoću događaja na osnovu njegove učestalosti i procijenimo grešku ove aproksimacije.
Hajde da izvedemo veliki broj eksperimenata P(bacite novčić), pronađite učestalost događaja A i želimo da procenimo njegovu verovatnoću R.
Iz zakona velikih brojeva P slijedi da:
Sada procijenimo praktično moguću grešku približne jednakosti (9.7). Da bismo to učinili, koristimo nejednakost (9.5) u obliku:
Naći R By R trebamo riješiti nejednačinu (9.8), da bismo to učinili moramo je kvadratirati i riješiti odgovarajuću kvadratna jednačina. Kao rezultat dobijamo:
Gdje 
Za grubu procjenu R By R može biti u formuli (9.8) R na desnoj zameni sa R ili u formulama (9.10), (9.11) pretpostaviti da

Tada dobijamo:
Pusti unutra P= 400 eksperimenata dobijena je vrijednost frekvencije R= 0,25, tada sa nivoom pouzdanosti od y = 0,95 nalazimo:
Šta ako trebamo preciznije znati vjerovatnoću, s greškom od, recimo, ne većom od 0,01? Da biste to učinili, potrebno je povećati broj eksperimenata.
Pretpostavljajući u formuli (9.12) vjerovatnoću R= 0.25, izjednačavamo vrijednost greške sa datom vrijednošću 0.01 i dobijamo jednačinu za P:

Rješavajući ovu jednačinu, dobijamo n~ 7500.
Razmotrimo sada još jedno pitanje: može li se odstupanje frekvencije od vjerovatnoće dobijene u eksperimentima objasniti slučajnim uzrocima, ili ovo odstupanje pokazuje da vjerovatnoća nije onakva kakvu smo očekivali? Drugim riječima, da li iskustvo potvrđuje prihvaćenu statističku hipotezu ili, obrnuto, zahtijeva da se ona odbaci?
Neka, na primjer, baci novčić P= 800 puta, dobijamo frekvenciju pojavljivanja grba R= 0,52. Sumnjali smo da je novčić asimetričan. Da li je ova sumnja opravdana? Da bismo odgovorili na ovo pitanje, poći ćemo od pretpostavke da je novčić simetričan (p = 0,5). Nađimo interval pouzdanosti (sa sigurnošću pouzdanosti at= 0,95) za učestalost pojavljivanja grba. Ako vrijednost dobijena u eksperimentu R= 0,52 se uklapa u ovaj interval - sve je normalno, prihvaćena hipoteza o simetriji novčića nije u suprotnosti s eksperimentalnim podacima. Formula (9.12) at R= 0,5 daje interval od 0,5 ± 0,035; primljenu vrijednost p = 0,52 se uklapa u ovaj interval, što znači da će novčić morati biti "očišćen" od sumnji na asimetriju.
Slične metode se koriste za procjenu da li su različita odstupanja od matematičkog očekivanja uočena u slučajnim pojavama slučajna ili „značajna“. Na primjer, da li je manjak težine slučajno pronađen u nekoliko uzoraka upakovane robe, ili to ukazuje na sistematsko obmanjivanje kupaca? Da li se stopa oporavka slučajno povećala kod pacijenata koji su koristili novi lijek ili je to zbog djelovanja lijeka?
Normalni zakon posebno igra važnu ulogu u teoriji vjerovatnoće i njenim praktičnim primjenama. Već smo vidjeli iznad da je slučajna varijabla - broj pojavljivanja nekog događaja u Bernoullijevoj shemi - sa P-» °° se svodi na normalni zakon. Međutim, postoji mnogo opštiji rezultat.
Centralna granična teorema. Zbir velikog broja nezavisnih (ili slabo zavisnih) slučajnih varijabli, međusobno uporedivih po redoslijedu njihovih varijansi, distribuira se prema normalnom zakonu, bez obzira na to kakvi su bili zakoni raspodjele pojmova. Gornja izjava je gruba kvalitativna formulacija centralne granične teorije. Ova teorema ima mnogo oblika, koji se međusobno razlikuju po uslovima koje slučajne varijable moraju da zadovolje da bi njihov zbir bio „normalizovan“ sa povećanjem broja članova.
Normalna gustina distribucije Dx) izražava se formulom:
Gdje A - matematičko očekivanje slučajne varijable X s= V7) je njegova standardna devijacija.
Za izračunavanje vjerovatnoće da x padne unutar intervala (x 1? x 2), koristi se integral:
Budući da se integral (9.14) pri gustini (9.13) ne može izraziti u terminima elementarne funkcije(“nije uzeto”), zatim za izračunavanje (9.14) koriste tabele kumulativne funkcije distribucije standardne normalne distribucije, kada a = 0, a = 1 (takve tabele su dostupne u bilo kom udžbeniku teorije verovatnoće):
Vjerovatnoća (9.14) korištenjem jednačine (10.15) izražava se formulom:
Primjer. Pronađite vjerovatnoću da je slučajna varijabla X, ima normalnu distribuciju sa parametrima A, a će odstupiti od svog matematičkog očekivanja po modulu za najviše 3.
Koristeći formulu (9.16) i tabelu funkcije distribucije normalnog zakona, dobijamo:
Primjer. U svakom od 700 nezavisnih eksperimenata događaj A dešava se sa konstantnom vjerovatnoćom R= 0,35. Nađite vjerovatnoću da će događaj A desiće se:
- 1) tačno 270 puta;
- 2) manje od 270, a više od 230 puta;
- 3) više od 270 puta.
Pronalaženje matematičkog očekivanja A = itd i standardna devijacija:
![]()
slučajna varijabla - broj pojavljivanja događaja O:

Pronalaženje centrirane i normalizirane vrijednosti X:

Iz tablica gustine normalne raspodjele nalazimo f(x):
![]()

Nađimo ga sada R w (x,> 270) = P 700 (270 F(1,98) = = 1 - 0,97615 = 0,02385.
Ozbiljan korak u istraživanju problema velikih brojeva napravio je 1867. P. L. Čebišev. On je razmatrao vrlo opšti slučaj kada se od nezavisnih slučajnih varijabli ništa ne traži osim postojanja matematičkih očekivanja i varijansi.
Čebiševljeva nejednakost. Za proizvoljno mali pozitivan broj e vrijedi sljedeća nejednakost:
Čebiševljeva teorema. Ako x x, x 2, ..., x p - parno nezavisne slučajne varijable, od kojih svaka ima matematičko očekivanje E(Xj) = ci i varijansu D(x,) =), a varijanse su uniformno ograničene, tj. 1,2 ..., tada za bilo koji proizvoljno mali pozitivan broj e važi sljedeća relacija:
Posljedica. Ako a,= aio, -o 2 , i= 1,2 ..., dakle
Zadatak. Koliko puta se novčić mora baciti da vjerovatnoća ne bude manja od y - 0,997, moglo bi se tvrditi da će učestalost ispadanja grba biti u intervalu (0,499; 0,501)?
Pretpostavimo da je novčić simetričan, p - q - 0.5. Primijenimo Čebiševljevu teoremu u formuli (9.19) na slučajnu varijablu X- učestalost pojavljivanja grba u P bacanja novčića. To smo već pokazali iznad X = X x + X 2 + ... +X„, Gdje X t - slučajna varijabla koja uzima vrijednost 1 ako je novčić glava, a vrijednost 0 ako je rep. dakle:
Zapišimo nejednakost (9.19) za događaj suprotan od događaja označenog pod znakom vjerovatnoće:

U našem slučaju [e = 0,001, cj 2 = /?-p)]t je broj pojavljivanja grba u P bacanje. Zamjenom ovih veličina u posljednju nejednakost i uzimajući u obzir da, prema uslovima problema, nejednakost mora biti zadovoljena, dobijamo:

Navedeni primjer ilustruje mogućnost korištenja Čebiševljeve nejednakosti za procjenu vjerovatnoća određenih odstupanja slučajnih varijabli (kao i probleme kao što je ovaj primjer koji se odnose na izračunavanje ovih vjerovatnoća). Prednost Čebiševe nejednakosti je u tome što ne zahtijeva poznavanje zakona raspodjele slučajnih varijabli. Naravno, ako je takav zakon poznat, onda Čebiševljeva nejednakost daje pregrube procjene.
Pogledajmo isti primjer, ali koristeći činjenicu da je bacanje novčića poseban slučaj Bernoullijeve šeme. Broj uspjeha (u primjeru - broj grbova) poštuje binomski zakon, a sa velikim P ovaj zakon se može predstaviti normalnim zakonom sa matematičkim očekivanjem zbog integralne Moivre-Laplaceove teoreme a = pr = n? 0,5 i sa standardnom devijacijom a = yfnpq - 25=0,5l/l. Slučajna varijabla - učestalost ispadanja grba - ima matematičko očekivanje = 0,5 i standardnu devijaciju

tada imamo:

Iz posljednje nejednakosti dobijamo:

Iz tablica normalne distribucije nalazimo:

Vidimo da normalna aproksimacija daje broj bacanja novčića koji daje zadatu grešku u procjeni vjerovatnoće grba, koji je 37 puta manji u odnosu na procjenu dobivenu korištenjem Čebiševljeve nejednakosti (ali Čebiševljeva nejednakost omogućava da se slični proračuni u slučaju kada nemamo informacije o zakonu raspodjele slučajne varijable koja se proučava).
Razmotrimo sada primijenjeni problem riješen korištenjem formule (9.16).
Problem konkurencije. Dvije konkurentske željezničke kompanije imaju po jedan voz između Moskve i Sankt Peterburga. Ovi vozovi su opremljeni približno isto, a polaze i dolaze u približno isto vrijeme. Pretvarajmo se to P= 1000 putnika samostalno i nasumično bira svoj voz, stoga, kao matematički model za izbor voza od strane putnika, koristimo Bernoullijevu šemu sa P izazove i izglede za uspjeh R= 0,5. Kompanija mora odlučiti koliko će sjedišta obezbijediti u vozu, uzimajući u obzir dva međusobno kontradiktorna uslova: s jedne strane, ne želite da imate prazna mjesta, s druge strane, ne želite da ljudi budu nezadovoljni nedostatak mjesta (sljedeći put će preferirati konkurentske kompanije). Naravno, može se obezbediti i u vozu P= 1000 mjesta, ali tada će očigledno biti praznih mjesta. Slučajna varijabla - broj putnika u vozu - u okviru usvojenog matematičkog modela koristeći Moivreovu integralnu teoriju - Laplace se pridržava normalnog zakona s matematičkim očekivanjem a = pr = n/2 i varijansa a 2 = npq = p/4 sekvencijalno. Vjerovatnoća da je više od s putnika, određuje se omjerom:

Postavite nivo rizika A, odnosno vjerovatnoća da će doći više s putnici: 
Odavde: 
Ako A je korijen rizika posljednje jednadžbe, koji se nalazi iz tablica funkcije distribucije normalnog zakona, onda dobijamo: 
ako npr. P = 1000, A= 0,01 (ovaj nivo rizika znači da je broj mjesta s tada će biti dovoljno u 99 slučajeva od 100). x a ~ 2.33 i s = 537 mjesta. Štaviše, ako obje kompanije prihvate isti nivo rizika A= 0,01, tada će dva voza imati ukupno 1074 sjedišta, od kojih će 74 biti prazna. Slično, može se izračunati da bi 514 mjesta bilo dovoljno u 80% svih slučajeva, a 549 mjesta bi bilo dovoljno u 999 od 1000 slučajeva.
Slična razmatranja vrijede i za druge konkurentske probleme usluga. Na primjer, ako T bioskopi se takmiče za isto P gledalaca, onda to treba prihvatiti R= -. Dobijamo,
koliki je broj sedišta s u kinu treba odrediti omjerom:

Ukupan broj praznih mjesta jednak je:

Za A = 0,01, P= 1000 i T= 2, 3, 4 vrijednosti ovog broja su približno jednake 74, 126, 147, respektivno.
Pogledajmo još jedan primjer. Neka se voz sastoji od P - 100 vagona. Težina svakog automobila je slučajna varijabla sa matematičkim očekivanjima A - 65 tona i očekivani srednji kvadrat o = 9 tona Lokomotiva može nositi voz ako njena težina ne prelazi 6600 tona; u suprotnom, morate priključiti drugu lokomotivu. Morate pronaći vjerovatnoću da to nećete morati učiniti.
težine pojedinačnih automobila:  , sa istim matematičkim očekivanjima A - 65 i ista varijansa d- o 2 = 81. Prema pravilu matematičkih očekivanja: E(x) - 100 * 65 = 6500. Prema pravilu sabiranja varijansi: D(x) = 100 x 81 = 8100. Izdvajanjem korijena nalazimo standardnu devijaciju. Da bi jedna lokomotiva vukla voz, težina voza mora biti X ispostavilo se kao ograničavajuće, tj. palo u interval (0; 6600). Slučajna varijabla x - zbir 100 članova - može se smatrati normalno distribuiranom. Koristeći formulu (9.16) dobijamo:
, sa istim matematičkim očekivanjima A - 65 i ista varijansa d- o 2 = 81. Prema pravilu matematičkih očekivanja: E(x) - 100 * 65 = 6500. Prema pravilu sabiranja varijansi: D(x) = 100 x 81 = 8100. Izdvajanjem korijena nalazimo standardnu devijaciju. Da bi jedna lokomotiva vukla voz, težina voza mora biti X ispostavilo se kao ograničavajuće, tj. palo u interval (0; 6600). Slučajna varijabla x - zbir 100 članova - može se smatrati normalno distribuiranom. Koristeći formulu (9.16) dobijamo:

Iz toga slijedi da će se lokomotiva „snaći“ sa vozom sa približnom vjerovatnoćom od 0,864. Smanjimo sada broj vagona u vozu za dva, tj. uzmimo P= 98. Sada računajući vjerovatnoću da će se lokomotiva „snaći“ sa vozom, dobijamo vrijednost reda 0,99, odnosno gotovo siguran događaj, iako su za to trebalo ukloniti samo dva vagona.
Dakle, ako imamo posla sa sumama velikog broja slučajnih varijabli, onda možemo koristiti normalni zakon. Naravno, ovo postavlja pitanje: koliko slučajnih varijabli treba dodati da bi zakon raspodjele sume već bio “normaliziran”? Zavisi od toga koji su zakoni distribucije termina. Postoje tako zamršeni zakoni da se normalizacija dešava samo sa veoma velikim brojem pojmova. Ali ove zakone su izmislili matematičari; priroda, po pravilu, namjerno ne stvara takve probleme. Obično je u praksi, da bi se mogao koristiti normalan zakon, dovoljno pet ili šest termina.
Brzina kojom se zakon raspodjele sume identično raspoređenih slučajnih varijabli „normalizira“ može se ilustrovati na primjeru slučajnih varijabli sa uniformnom distribucijom na intervalu (0, 1). Kriva takve raspodjele ima oblik pravokutnika, koji više nije sličan normalnom zakonu. Dodajmo dvije takve nezavisne varijable - dobijemo slučajnu varijablu raspoređenu prema tzv. Simpsonovom zakonu, grafička slika koji ima formu jednakokraki trougao. Takođe ne izgleda kao normalan zakon, ali je bolji. A ako zbrojite tri takve jednoliko raspoređene slučajne varijable, dobićete krivu koja se sastoji od tri segmenta parabole, vrlo slične normalnoj krivoj. Ako zbrojite šest takvih slučajnih varijabli, dobićete krivulju koja se ne razlikuje od normalne. Ovo je osnova za široko korišćenu metodu za dobijanje normalno raspoređene slučajne varijable, a svi savremeni računari su opremljeni senzorima za ravnomerno raspoređene (0, 1) slučajne brojeve.
Sljedeća metoda se preporučuje kao jedan praktičan način da se to provjeri. Konstruišemo interval pouzdanosti za učestalost događaja sa nivoom at= 0,997 prema pravilu tri sigma:

i ako oba njegova kraja ne idu dalje od segmenta (0, 1), onda se može koristiti normalni zakon. Ako je bilo koja od granica intervala povjerenja izvan segmenta (0, 1), tada se normalni zakon ne može koristiti. Međutim, pod nekim uslovima, binomni zakon za učestalost nekog slučajnog događaja, ako ne teži normalnom, onda može težiti drugom zakonu.
U mnogim aplikacijama, Bernulijeva shema se koristi kao matematički model slučajnog eksperimenta, u kojem se broj pokušaja P sjajno, slučajni događaj prilično retko, tj. R = itd nije mala, ali nije ni velika (fluktuira u rasponu od O -5-20). U ovom slučaju vrijedi granična relacija:
Formula (9.20) se zove Poissonova aproksimacija za binomski zakon, pošto se raspodjela vjerovatnoće na njenoj desnoj strani naziva Poissonov zakon. Za Poissonovu distribuciju se kaže da je distribucija vjerovatnoće za rijetke događaje jer se javlja kada su granice zadovoljene: P -»°°, R-»0, ali X = pr oo.
Primjer. Rođendani. Kolika je vjerovatnoća R t (k) to u društvu od 500 ljudi To ljudi su rođeni na Novu godinu? Ako se ovih 500 ljudi odabere nasumično, onda se Bernulijeva šema može primijeniti s vjerovatnoćom uspjeha P = 1/365. Onda

Proračuni vjerovatnoće za razne To dati sljedeće vrijednosti: RU = 0,3484...; R 2 = 0,2388...; R 3 = 0,1089...; P 4 = 0,0372...; R 5 = 0,0101...; R 6= 0,0023... Odgovarajuće aproksimacije koristeći Poissonovu formulu za X = 500 1/365 = 1,37
dati sljedeće vrijednosti: Ru = 0,3481...; R 2 = 0,2385...; P ʺ = 0,1089; R 4 = 0,0373...; P 5 = 0,0102...; P 6 = 0,0023... Sve greške su samo na četvrtom decimalu.
Evo primjera situacija u kojima možete koristiti Poissonov zakon rijetkih događaja.
Na telefonskoj centrali se javlja pogrešna veza sa malom vjerovatnoćom R, obično R~0,005. Tada nam Poissonova formula omogućava da pronađemo vjerovatnoću netačnih veza za datu ukupan broj veze n~ 1000 kada X = pr =1000 0,005 = 5.
Kada pečete lepinje, u tijesto dodajte grožđice. Zbog miješanja, treba očekivati da će učestalost pečenja s grožđicama približno slijediti Poissonovu distribuciju R p (k, X), Gdje X- gustina grožđica u testu.
Radioaktivna supstanca emituje i-čestice. Događaj koji broj d-čestica dostiže tokom vremena t datoj površini prostora, uzima fiksnu vrijednost za, poštuje Poissonov zakon.
Broj živih ćelija sa izmenjenim hromozomima kada su izložene rendgenskim zracima prati Poissonovu distribuciju.
Dakle, zakoni velikih brojeva nam omogućavaju da riješimo problem matematičke statistike, povezano s procjenom nepoznatih vjerovatnoća elementarnih ishoda slučajnog eksperimenta. Zahvaljujući ovom znanju, metode teorije vjerovatnoće činimo praktičnim smislenim i korisnim. Zakoni velikih brojeva također omogućavaju rješavanje problema dobijanja informacija o nepoznatim elementarnim vjerovatnoćama u drugom obliku - obliku testiranja statističkih hipoteza.
Razmotrimo detaljnije formulaciju i probabilistički mehanizam za rješavanje problema testiranja statističkih hipoteza.