Primjer rješenja je empirijska funkcija distribucije. Empirijska funkcija raspodjele, svojstva. Varijacijska serija. Poligon i histogram
Neka X 1 , X 2 , ..., X n-- zapremina uzorkovanja P iz populacije sa distributivnom funkcijom F(x). Ako rasporedite uzorke podataka u neopadajućem redoslijedu, rezultujuća serija se poziva varijantne serije: X (1) , X (2) , ..., X (n)
Primjer 1. Ako je uzorak volumena 4 sljedeći: 4, -2, 3, 1, tada serija varijacija izgleda ovako: -2, 1, 3, 4.
Definicija 1. Poziva se empirijska funkcija raspodjele F(x) diskretno slučajna varijabla, čija tabela distribucije izgleda ovako:
Kao što je prikazano u 2.2.1, funkcija distribucije diskretne slučajne varijable

ima sljedeći oblik:

Drugim riječima F n (x) = v/n, Gdje v--broj tih vrijednosti uzorka X i , koji su manji X.

Kao što se može vidjeti iz grafikona, funkcija F n (x) je stepenasto i ima diskontinuitet u tačkama X (i) a veličina skoka je 1 /n, ako se vrijednosti poklapaju jedna s drugom X i , br. Ako k vrijednosti X (i) poklapaju, tada je veličina skoka u ovoj tački jednaka k/n.
Zanimljivo je ograničavajuće ponašanje F n (x) at P.
Teorema 1. Neka X 1 , X 2 , ..., X n --veličina uzorka n iz populacije pomoću funkcije distribucije F(x). Tada kada je n co za bilo koji x 1 fer
F n (x) P F(x),
ili, drugim riječima, za bilo koji > 0,
Dokaz. Neka

diskretne slučajne varijable takve da je P( i == 0) = q i P( i = 1) = p, i = 1. 2..... P. Lako je to vidjeti

Onda po zakonu veliki brojevi(vidi 2.7.2) za empirijsku funkciju distribucije F n (x) = 1/n n i=1 i kod n dobijamo
F n (x) P F(x),
Prije nego što formulišemo još jednu teoremu, izlažemo sljedeća definicija.
Definicija 2. Niz slučajnih varijabli 1 , 2 , …, n , … konvergira sa verovatnoćom 1 (jedan) (ili gotovo sigurno), ako vrijedi sljedeća jednakost
Sada formulirajmo (bez dokaza, može se naći u) sljedeću teoremu.
Teorema 2 (Glivenko - Cantelli). Pod uslovima prethodne teoreme, to je tačno
Ovi rezultati pokazuju da u cjelini P empirijska funkcija raspodjele daje dobru aproksimaciju teorijskoj funkciji distribucije F(x).
Volume samples P iz populacije sa kontinuiranom distribucijom F(x) u praksi su često podložni grupisanju. U ovom slučaju nisu naznačene vrijednosti uzorka, već broj vrijednosti uzorka koje spadaju u intervale neke specifične particije opće populacije (podjela skupa mogućih vrijednosti slučajne varijable koji ima funkciju distribucije F(x) ). Po pravilu se uzimaju intervali iste dužine, recimo h. Ako označimo sa n i broj uzoraka vrijednosti uključenih u i- interval, onda se ovaj interval uzima kao osnova pravougaonika visine n i /nh. Rezultirajuća figura se zove uzorak histograma. Površina svakog pravokutnika histograma jednaka je frekvenciji n i /n odgovarajuću grupu. Na slobodi P ova površina će biti približno jednaka vjerovatnoći pada u odgovarajući interval, tj. će biti približno jednak integralu gustine raspodjele p( t), izračunato u ovom intervalu. Dakle, gornji dio konture histograma daje dobru aproksimaciju za gustinu distribucije.
Primjer 2. Testirana je osjetljivost 1. kanala n = 40 televizora. Podaci testa prikazani su u sljedećoj tabeli, gdje prvi red daje intervale osjetljivosti u mikrovoltima, drugi - broj televizora čija je osjetljivost pronađena u ovom intervalu:

Ovdje je dužina intervala h = 50. Napravimo histogram.
Metode obrade ED baziraju se na osnovnim konceptima teorije vjerovatnoće i matematičke statistike. To uključuje koncepte opće populacije, uzorka, empirijske funkcije distribucije.
Ispod opšta populacija razumiju sve moguće vrijednosti parametara koje se mogu snimiti tokom neograničenog vremenskog posmatranja objekta. Takav skup se sastoji od beskonačnog broja elemenata. Kao rezultat promatranja objekta formira se skup vrijednosti parametara ograničenog volumena x 1 , x 2 , …, xn. Sa formalne tačke gledišta, takvi podaci predstavljaju uzorak iz opšte populacije.
Pretpostavit ćemo da uzorak sadrži kompletan razvoj prije sistemskih događaja (nema cenzure). Uočene vrijednosti x i pozvao opcije , a njihov broj je veličina uzorka n. Da bi se iz rezultata posmatranja izvukli bilo kakvi zaključci, uzorak mora biti predstavnik(reprezentativni), odnosno ispravno predstavljaju proporcije opšte populacije. Ovaj zahtjev je ispunjen ako je veličina uzorka dovoljno velika i svaki element u populaciji ima istu vjerovatnoću da bude uključen u uzorak.
Neka rezultirajući uzorak ima vrijednost x Uočen je 1 parametar n 1 put, vrijednost x 2 – n 2 puta, znači xk – nk jednom, n 1 +n 2 + … +nk=n.
Poziva se skup vrijednosti napisanih u rastućem redoslijedu varijantne serije, količine n i – frekvencije i njihov odnos prema veličini uzorka ni=n i /n – relativne frekvencije(frekvencije). Očigledno, zbir relativnih frekvencija je jednak jedinici.
Distribucija se odnosi na korespondenciju između posmatranih varijanti i njihovih frekvencija ili frekvencija. Neka nx
– broj opservacija u kojima su slučajne vrijednosti parametra X manje x. Učestalost događaja X
distribucije: Fn(x) neopadajuća funkcija, njene vrijednosti pripadaju segmentu;
Ako x 1 je najmanja vrijednost parametra, i xk – onda najveći Fn(x)= 0, Kada x<x 1 , I FP(xk)= 1 kada x>=xk.
Funkcija Fn(x) određuje ED, zbog čega se i zove empirijska funkcija distribucije. Za razliku od empirijske funkcije Fn(x) funkcija distribucije F (x) populacije naziva se teorijska funkcija raspodjele, ne karakteriše učestalost, već vjerovatnoću događaja X<x. Iz Bernoullijeve teoreme slijedi da je frekvencija Fn(x) teži u vjerovatnoći vjerovatnoći F(x) sa neograničenim uvećanjem n. Posljedično, uz veliki obim zapažanja, teorijska funkcija distribucije F(x) može se zamijeniti empirijskom funkcijom Fn(x).
Grafikon empirijske funkcije Fn(x) je isprekidana linija. U prostorima između susjednih članova varijacionog niza Fn(x) ostaje konstantan. Prilikom prolaska kroz tačke osi x, jednak članovima uzorka, Fn(x) prolazi kroz diskontinuitet, naglo se povećava za vrijednost 1/ n, i ako postoji slučajnost l zapažanja - na l/n.
Primjer 2.1. Konstruirati varijacioni niz i graf empirijske funkcije raspodjele na osnovu rezultata promatranja, tabela. 2.1.
Tabela 2.1
Željena empirijska funkcija, Sl. 2.1:

Rice. 2.1. Empirijska funkcija distribucija
Uz veliku veličinu uzorka (koncept „velikog volumena“ ovisi o ciljevima i metodama obrade, u ovom slučaju ćemo razmotriti P veliko ako n>40) radi pogodnosti obrade i skladištenja informacija pribjegavajte grupisanju ED-ova u intervale. Broj intervala treba odabrati tako da se raznolikost vrijednosti parametara u zbiru odražava u potrebnoj mjeri, a da istovremeno obrazac distribucije ne bude iskrivljen slučajnim fluktuacijama frekvencije u pojedinačnim kategorijama. Postoje labave smjernice za odabir količine y I veličina h takvi intervali, posebno:
svaki interval mora sadržavati najmanje 5-7 elemenata. U ekstremnim rangovima, dozvoljena su samo dva elementa;
broj intervala ne bi trebao biti veliki ili vrlo mali. Minimum vrijednost y mora biti najmanje 6 – 7. Uz veličinu uzorka koja ne prelazi nekoliko stotina elemenata, vrijednost y je postavljen u rasponu od 10 do 20. Za veoma veliku veličinu uzorka ( n>1000) broj intervala može premašiti navedene vrijednosti. Neki istraživači preporučuju korištenje omjera y=1,441*ln( n)+1;
sa relativno malim nejednakostima u dužini intervala, pogodno je odabrati isti i jednak vrijednosti
h= (x max – x min)/g,
Gdje x max – maksimum i x min – minimalna vrijednost parametra. Ako je zakon raspodjele značajno neujednačen, dužina intervala se može podesiti na manju veličinu u području brzih promjena gustine distribucije;
Ako postoji značajna neujednačenost, bolje je svakoj kategoriji dodijeliti približno isti broj elemenata uzorka. Tada će dužina određenog intervala biti određena ekstremnim vrijednostima elemenata uzorka grupiranih u ovaj interval, tj. bit će različita za različite intervale (u ovom slučaju, kada se gradi histogram, potrebna je normalizacija po dužini intervala - inače će visina svakog elementa histograma biti ista).
Grupisanje rezultata posmatranja po intervalima omogućava: određivanje opsega promena parametra X; odabir broja intervala i njihove veličine; računajući za sve ja- th interval [ xi–xi+1 ] frekvencije ni ili relativna frekvencija (frekvencija n i) opcije spadaju u interval. Kao rezultat, reprezentacija ED se formira u obliku interval ili statistička serija.
Grafički se statistička serija prikazuje u obliku histograma, poligona i stepenaste linije. Često histogram predstavljen kao figura koja se sastoji od pravougaonika, čije su osnove intervali dužine h, a visine su jednake odgovarajućoj frekvenciji. Međutim, ovaj pristup je netačan. Visina ja- th pravougaonik z i treba izabrati jednaku ni/ (nh). Takav histogram se može tumačiti kao grafički prikaz empirijske funkcije distribucije fn(x), u njemu će ukupna površina svih pravokutnika biti jedna. Histogram pomaže u odabiru tipa teorijske funkcije distribucije za aproksimaciju ED.
Poligon naziva se izlomljena linija, čiji segmenti povezuju tačke sa koordinatama duž apscisne ose jednake sredinama intervala, a duž ordinatne ose jednake odgovarajućim frekvencijama. Empirijska funkcija distribucije je prikazana kao stepenasta isprekidana linija: horizontalni segment linije je nacrtan preko svakog intervala na visini proporcionalnoj akumuliranoj frekvenciji u trenutnom intervalu. Akumulirana frekvencija jednaka je zbiru svih frekvencija, počevši od prvog pa do ovog intervala uključujući.
Primjer 2.2. Postoje rezultati snimanja vrijednosti slabljenja signala xi na frekvenciji od 1000 Hz komutiranog kanala telefonske mreže. Ove vrijednosti, mjerene u dB, prikazane su u obliku varijacionog niza u tabeli. 2.3. Neophodno je konstruisati statističku seriju.
Tabela 2.3
| i | |||||||||||
| xi | 25,79 | 25,98 | 25,98 | 26,12 | 26,13 | 26,49 | 26,52 | 26,60 | 26,66 | 26,69 | 26,74 |
| i | |||||||||||
| xi | 26,85 | 26,90 | 26,91 | 26,96 | 27,02 | 27,11 | 27,19 | 27,21 | 27,28 | 27,30 | 27,38 |
| i | |||||||||||
| xi | 27,40 | 27,49 | 27,64 | 27,66 | 27,71 | 27,78 | 27,89 | 27,89 | 28,01 | 28,10 | 28,11 |
| i | |||||||||||
| xi | 28,37 | 28,38 | 28,50 | 28,63 | 28,67 | 28,90 | 28,99 | 28,99 | 29,03 | 29,12 | 29,28 |
Rješenje. Broj cifara statističke serije treba odabrati što je moguće minimalniji kako bi se osigurao dovoljan broj pogodaka u svakoj od njih, uzmimo y = 6. Odredimo veličinu cifre
h =(x max – x min)/y =(29,28 – 25,79)/6 = 0,58.
Grupirajmo opažanja po kategorijama, tabela. 2.4.
Tabela 2.4
| i | ||||||
| xi | 25,79 | 26,37 | 26,95 | 27,5 3 | 28,12 | 28,70 |
| ni | ||||||
| n i=ni/n | 0,114 | 0,205 | 0,227 | 0,205 | 0,11 4 | 0,136 |
| z i =n i /h | 0,196 | 0,353 | 0,392 | 0,353 | 0,196 | 0,235 |
Na osnovu statističke serije napravićemo histogram, Sl. 2.2, i graf empirijske funkcije distribucije, Sl. 2.3.
Grafikon empirijske funkcije distribucije, Sl. 2.3 razlikuje se od grafikona prikazanog na Sl. 2.1 jednakost koraka promjene opcija i veličine koraka prirasta funkcije (kada se konstruira korištenjem niza varijacija, korak povećanja je višestruki
1/ n, a prema statističkoj seriji - zavisi od učestalosti u pojedinoj kategoriji).

Razmatrani ED prikazi su početni za naknadnu obradu i proračun različitih parametara.
Kao što je poznato, zakon raspodjele slučajne varijable može se specificirati na različite načine. Diskretna slučajna varijabla se može specificirati korištenjem distribucijske serije ili integralne funkcije, a kontinuirana slučajna varijabla može se specificirati korištenjem integralne ili diferencijalne funkcije. Razmotrimo selektivne analoge ove dvije funkcije.
Neka postoji uzorak skupa vrijednosti neke slučajne varijable volumena  i svaka opcija iz ovog skupa je povezana sa svojom frekvencijom. Neka dalje
i svaka opcija iz ovog skupa je povezana sa svojom frekvencijom. Neka dalje  – neke pravi broj, A
– neke pravi broj, A  – broj uzoraka vrijednosti slučajne varijable
– broj uzoraka vrijednosti slučajne varijable  , manji
, manji  .Onda broj
.Onda broj  je učestalost kvantitetnih vrijednosti uočenih u uzorku X, manji
je učestalost kvantitetnih vrijednosti uočenih u uzorku X, manji  ,
one. učestalost pojavljivanja događaja
,
one. učestalost pojavljivanja događaja 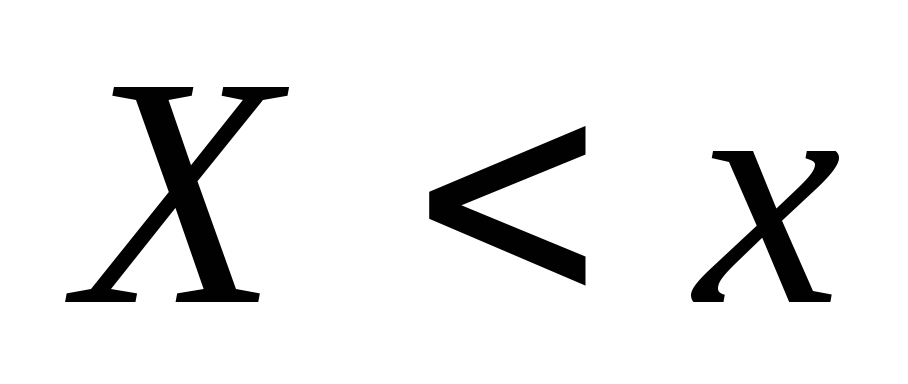 . Kada se promeni x u opštem slučaju, vrednost će se takođe promeniti
. Kada se promeni x u opštem slučaju, vrednost će se takođe promeniti  . To znači da je relativna frekvencija
. To znači da je relativna frekvencija  je funkcija argumenta
je funkcija argumenta  . A budući da se ova funkcija nalazi iz uzoraka podataka dobivenih kao rezultat eksperimenata, naziva se selektivnim ili empirijski.
. A budući da se ova funkcija nalazi iz uzoraka podataka dobivenih kao rezultat eksperimenata, naziva se selektivnim ili empirijski.
Definicija 10.15. Empirijska funkcija distribucije(funkcija distribucije uzorkovanja) je funkcija  , definiranje za svaku vrijednost x relativna učestalost događaja
, definiranje za svaku vrijednost x relativna učestalost događaja  .
.
 (10.19)
(10.19)
Za razliku od empirijske funkcije distribucije uzorkovanja, funkcija distribucije F(x) opšte populacije naziva se teorijska funkcija distribucije. Razlika između njih je u teorijskoj funkciji F(x)
određuje vjerovatnoću događaja  , a empirijski je relativna učestalost istog događaja. Iz Bernoullijeve teoreme slijedi
, a empirijski je relativna učestalost istog događaja. Iz Bernoullijeve teoreme slijedi
 ,
,
 (10.20)
(10.20)
one. na slobodi  vjerovatnoća
vjerovatnoća  i relativnu učestalost događaja
i relativnu učestalost događaja  , tj.
, tj.  malo se razlikuju jedno od drugog. Iz ovoga slijedi da je preporučljivo koristiti empirijsku funkciju distribucije uzorka za aproksimaciju teorijske (integralne) funkcije raspodjele opće populacije.
malo se razlikuju jedno od drugog. Iz ovoga slijedi da je preporučljivo koristiti empirijsku funkciju distribucije uzorka za aproksimaciju teorijske (integralne) funkcije raspodjele opće populacije.
Funkcija  I
I  imaju ista svojstva. Ovo slijedi iz definicije funkcije.
imaju ista svojstva. Ovo slijedi iz definicije funkcije. 
Svojstva  :
:

Primjer 10.4. Konstruirajte empirijsku funkciju na osnovu date distribucije uzorka:
|
Opcije | |||
|
Frekvencije |


Rješenje: Nađimo veličinu uzorka n=
12+18+30=60. Najmanja opcija  , dakle,
, dakle,  at
at  . Značenje
. Značenje  , naime
, naime  posmatrano 12 puta, dakle:
posmatrano 12 puta, dakle:
 =
= at
at  .
.
Značenje x<
10, naime  I
I  posmatrano 12+18=30 puta, dakle,
posmatrano 12+18=30 puta, dakle,  =
=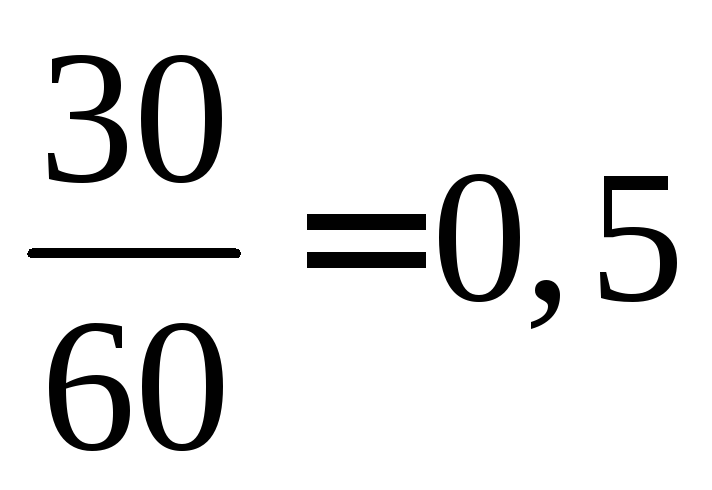 at
at  . At
. At 
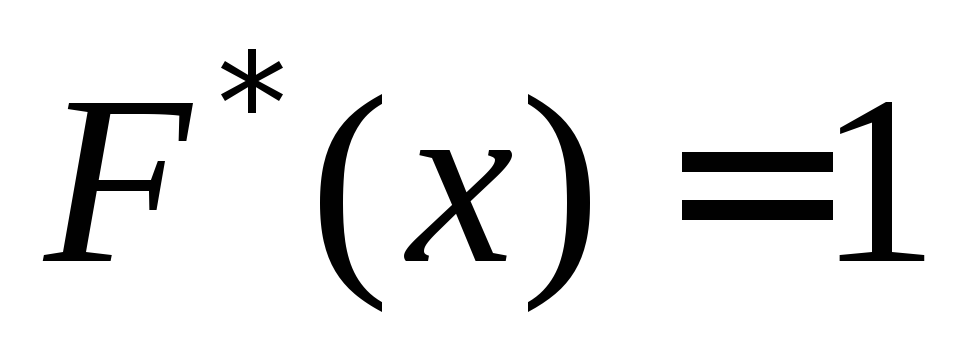 .
.
Tražena empirijska funkcija distribucije:
 =
=
Raspored  prikazano na sl. 10.2
prikazano na sl. 10.2
R  je. 10.2
je. 10.2
Kontrolna pitanja
1. Koje glavne probleme rješava matematička statistika? 2. Opća i uzorkovana populacija? 3. Definirajte veličinu uzorka. 4. Koji se uzorci nazivaju reprezentativnim? 5. Greške reprezentativnosti. 6. Osnovne metode uzorkovanja. 7. Koncepti frekvencije, relativne frekvencije. 8. Koncept statističkih serija. 9. Zapišite Sturgesovu formulu. 10. Formulirajte koncepte raspona uzorka, medijana i moda. 11. Frekvencijski poligon, histogram. 12. Koncept bodovne procjene populacije uzorka. 13. Pristrasna i nepristrasna procjena bodova. 14. Formulirajte koncept prosjeka uzorka. 15. Formulirajte koncept varijanse uzorka. 16. Formulirajte koncept standardne devijacije uzorka. 17. Formulirati koncept koeficijenta varijacije uzorka. 18. Formulirajte koncept uzorka geometrijske sredine.
Prosek uzorka.
Neka se izdvoji uzorak veličine n da bi se proučavala opšta populacija u pogledu kvantitativne karakteristike X.
Srednja vrijednost uzorka je aritmetička sredina karakteristike u populaciji uzorka.
![]()
Varijanca uzorka.
Da bi se uočila disperzija kvantitativne karakteristike vrijednosti uzorka oko njene prosječne vrijednosti, uvodi se zbirna karakteristika - varijansa uzorka.
Varijanca uzorka je aritmetička sredina kvadrata odstupanja posmatranih vrijednosti karakteristike od njihove srednje vrijednosti.
Ako su sve vrijednosti karakteristike uzorka različite, onda

Ispravljena varijansa.
Varijanca uzorka je pristrasna procjena varijanse populacije, tj. matematičko očekivanje varijanse uzorka nije jednako procijenjenoj opštoj varijansi, ali je jednako
![]()
Da biste ispravili varijansu uzorka, jednostavno je pomnožite s razlomkom
Koeficijent korelacije uzorka nalazi se po formuli

gdje su standardne devijacije vrijednosti uzorka i .
Koeficijent korelacije uzorka pokazuje bliskost linearne veze između i : što je bliže jedinici, to je jača linearna veza između i .
23. Frekvencijski poligon je izlomljena linija čiji segmenti spajaju tačke. Da bi se konstruisao poligon frekvencija, varijante su iscrtane na osi apscisa, a odgovarajuće frekvencije su nacrtane na osi ordinata, a tačke su povezane linijskim segmentima.
Poligon relativne frekvencije se konstruiše na sličan način, osim što su relativne frekvencije iscrtane na osi ordinata.
Histogram frekvencije je stepenasta figura koja se sastoji od pravokutnika, čije su osnove parcijalni intervali dužine h, a visine su jednake omjeru. Za konstruiranje histograma frekvencije, parcijalni intervali se postavljaju na os apscise, a segmenti paralelni s osom apscise na udaljenosti (visini) se crtaju iznad njih. Površina i-tog pravougaonika jednaka je zbiru frekvencija i-o intervala, stoga je površina histograma frekvencije jednaka zbiru svih frekvencija, tj. veličina uzorka.


Empirijska funkcija distribucije
Gdje n x- broj vrijednosti uzorka manji od x; n- veličina uzorka.
22 Definirajmo osnovne koncepte matematičke statistike
.Osnovni pojmovi matematičke statistike. Populacija i uzorak. Varijabilne serije, statističke serije. Grupirani uzorak. Grupirane statističke serije. Frekvencijski poligon. Funkcija distribucije uzorka i histogram.
Populacija– cijeli skup dostupnih objekata.
Uzorak– skup objekata nasumično odabranih iz opće populacije.
Poziva se niz opcija napisanih u rastućem redoslijedu varijacijski u blizini i listu opcija i njihovih odgovarajućih frekvencija ili relativnih frekvencija - statističke serije: nasumično odabrano iz opće populacije.
Poligon frekvencije se naziva izlomljena linija, čiji segmenti spajaju tačke.
Histogram frekvencije je stepenasta figura koja se sastoji od pravokutnika, čije su osnovice parcijalni intervali dužine h, a visine su jednake omjeru .
Uzorak (empirijska) funkcija distribucije pozovite funkciju f*(x), definiranje za svaku vrijednost X relativna učestalost događaja X< x.
Ako se proučava neka kontinuirana karakteristika, tada se varijacijski niz može sastojati od vrlo velikog broja brojeva. U ovom slučaju je praktičniji za korištenje grupisani uzorak. Da bi se dobio, interval koji sadrži sve promatrane vrijednosti atributa dijeli se na nekoliko jednakih parcijalnih intervala dužine h, a zatim pronađite za svaki parcijalni interval n i– zbir frekvencija varijante uključene u i th interval.
20. Zakon velikih brojeva ne treba shvatiti kao bilo koji opšti zakon povezan sa velikim brojevima. Zakon velikih brojeva je generalizirani naziv za nekoliko teorema, iz kojih slijedi da s neograničenim povećanjem broja pokušaja prosječne vrijednosti teže određenim konstantama.
To uključuje teoreme Čebiševa i Bernulija. Čebiševljeva teorema je najopštiji zakon velikih brojeva.
Dokaz teorema, ujedinjen pojmom "zakon velikih brojeva", zasniva se na Čebiševovoj nejednakosti, koja utvrđuje vjerovatnoću odstupanja od svog matematičkog očekivanja:
![]()
19Pearsonova distribucija (hi - kvadrat) - raspodjela slučajne varijable
gdje su slučajne varijable X 1, X 2,…, X n nezavisni i imaju istu distribuciju N(0,1). U ovom slučaju, broj pojmova, tj. n, se naziva „broj stepena slobode“ hi-kvadrat raspodele.
Hi-kvadrat distribucija se koristi kada se procjenjuje varijansa (koristeći interval povjerenja), kada se testiraju hipoteze slaganja, homogenosti, nezavisnosti,
Distribucija t Studentov t je distribucija slučajne varijable
gdje su slučajne varijable U I X nezavisni, U ima standardnu normalnu distribuciju N(0.1), i X– hi raspodjela – kvadrat c n stepena slobode. Gde n se naziva „broj stepena slobode“ Studentove distribucije.
Koristi se pri procjeni matematičkog očekivanja, vrijednosti prognoze i drugih karakteristika korištenjem intervala povjerenja, testiranja hipoteza o vrijednostima matematičkih očekivanja, koeficijenata regresije,
Fisherova distribucija je distribucija slučajne varijable
Fisherova distribucija se koristi kada se testiraju hipoteze o adekvatnosti modela u regresiona analiza, o jednakosti varijansi i drugim problemima primijenjene statistike
18Linearna regresija je statistički alat koji se koristi za predviđanje budućih cijena na osnovu prošlih podataka i obično se koristi za određivanje kada su cijene pregrijane. Korištena metoda najmanji kvadrat da se konstruiše prava linija „najbolje uklapanje“ kroz niz tačaka vrednosti cene. Cenovne tačke koje se koriste kao ulaz mogu biti bilo koje od sledećeg: otvorene, zatvorene, visoke, niske,
17. Dvodimenzionalna slučajna varijabla je uređeni skup od dvije slučajne varijable ili .
Primjer: Bacaju se dvije kockice. – broj bodova bačenih na prvoj i drugoj kocki, respektivno
Univerzalna metoda specificiranje zakona distribucije dvodimenzionalne slučajne varijable je funkcija distribucije.
15.m.o Diskretne slučajne varijable
Svojstva:
1) M(C) = C, C- konstantan;
2) M(CX) = CM.(X);
3) M(X 1 + X 2) = M(X 1) + M(X 2), Gdje X 1, X 2- nezavisne slučajne varijable;
4) M(X 1 X 2) = M(X 1)M(X 2).
Očekivana vrijednost zbir slučajnih varijabli jednak je zbiru njihovih matematičkih očekivanja, tj.
Matematičko očekivanje razlike između slučajnih varijabli jednako je razlici njihovih matematičkih očekivanja, tj.
Matematičko očekivanje proizvoda slučajnih varijabli jednako je proizvodu njihovih matematičkih očekivanja, tj.
Ako se sve vrijednosti slučajne varijable povećaju (smanje) za isti broj C, tada će se njeno matematičko očekivanje povećati (smanjiti) za isti broj
14. Eksponencijalno(eksponencijalna)zakon o distribuciji X ima eksponencijalni zakon raspodjele s parametrom λ >0 ako njegova gustina vjerovatnoće ima oblik:
![]()
Očekivana vrijednost: .
Disperzija: .
Zakon eksponencijalne raspodjele igra veliku ulogu u teoriji queuing i teorije pouzdanosti.
13. Zakon normalne distribucije karakterizira učestalost otkaza a (t) ili gustina vjerovatnoće otkaza f (t) u obliku:
 , (5.36)
, (5.36)
gdje je σ standardna devijacija SV x;
m x– matematičko očekivanje SV x. Ovaj parametar se često naziva centar disperzije ili najvjerovatnija vrijednost SV X.
x– slučajna varijabla, koja se može uzeti kao vrijeme, vrijednost struje, vrijednost električnog napona i drugi argumenti.
Normalni zakon je zakon sa dva parametra, za pisanje kojeg trebate znati m x i σ.
Normalna distribucija (Gaussova distribucija) se koristi za procjenu pouzdanosti proizvoda na koje utječe niz nasumičnih faktora, od kojih svaki ima blagi utjecaj na rezultirajući učinak
12. Zakon o jedinstvenoj distribuciji. Kontinuirana slučajna varijabla X ima uniforman zakon raspodjele na segmentu [ a, b], ako je njegova gustina vjerovatnoće konstantna na ovom segmentu i jednaka nuli izvan njega, tj.

Oznaka: .
Očekivana vrijednost: .
Disperzija: .
Slučajna vrijednost X, distribuiran prema uniformnom zakonu na segmentu se zove slučajni broj od 0 do 1. Služi kao polazni materijal za dobijanje slučajnih varijabli sa bilo kojim zakonom raspodjele. Ujednačeni zakon distribucije koristi se u analizi grešaka zaokruživanja pri izvođenju numeričkih proračuna, u nizu problema čekanja, u statističkom modeliranju opservacija koje su predmet date raspodjele.
11. Definicija. Gustina distribucije vjerovatnoća kontinuirane slučajne varijable X naziva se funkcija f(x)– prvi izvod funkcije distribucije F(x).
Gustina distribucije se također naziva diferencijalna funkcija. Za opis diskretne slučajne varijable, gustina distribucije je neprihvatljiva.
Značenje gustine distribucije je da pokazuje koliko se često slučajna varijabla X pojavljuje u određenom susjedstvu tačke X pri ponavljanju eksperimenata.
Nakon uvođenja funkcija raspodjele i gustine distribucije, može se dati sljedeća definicija kontinuirane slučajne varijable.
10. Gustoća vjerovatnoće, gustina distribucije vjerovatnoće slučajne varijable x, je funkcija p(x) takva da 
i za bilo koje a< b вероятность события a < x < b равна
.
Ako je p(x) kontinuiran, onda je za dovoljno mali ∆x vjerovatnoća nejednakosti x< X < x+∆x приближенно равна p(x) ∆x (с точностью до малых более высокого порядка). Функция распределения F(x) случайной величины x, связана с плотностью распределения соотношениями
i ako je F(x) diferencijabilna, onda ![]()
Određivanje empirijske funkcije distribucije
Neka je $X$ slučajna varijabla. $F(x)$ je funkcija distribucije date slučajne varijable. Provešćemo $n$ eksperimente na datoj slučajnoj promenljivoj pod istim uslovima, nezavisno jedan od drugog. U ovom slučaju dobijamo niz vrijednosti $x_1,\ x_2\ $, ... ,$\ x_n$, koji se naziva uzorak.
Definicija 1
Svaka vrijednost $x_i$ ($i=1,2\ $, ... ,$ \ n$) naziva se varijanta.
Jedna procjena teorijske funkcije distribucije je empirijska funkcija distribucije.
Definicija 3
Empirijska funkcija distribucije $F_n(x)$ je funkcija koja za svaku vrijednost $x$ određuje relativnu frekvenciju događaja $X \
gdje je $n_x$ broj opcija manji od $x$, $n$ je veličina uzorka.
Razlika između empirijske funkcije i teorijske je u tome što teorijska funkcija određuje vjerovatnoću događaja $X
Svojstva empirijske funkcije distribucije
Razmotrimo sada nekoliko osnovnih svojstava funkcije distribucije.
Opseg funkcije $F_n\left(x\right)$ je segment $$.
$F_n\left(x\right)$ je neopadajuća funkcija.
$F_n\left(x\right)$ je lijeva kontinuirana funkcija.
$F_n\left(x\right)$ je konstantna funkcija po komadima i raste samo u tačkama vrijednosti slučajne varijable $X$
Neka je $X_1$ najmanja, a $X_n$ najveća opcija. Tada je $F_n\left(x\right)=0$ za $(x\le X)_1$ i $F_n\left(x\right)=1$ za $x\ge X_n$.
Hajde da uvedemo teoremu koja povezuje teorijske i empirijske funkcije.
Teorema 1
Neka je $F_n\left(x\right)$ empirijska funkcija raspodjele, a $F\left(x\right)$ teorijska funkcija raspodjele općeg uzorka. Tada vrijedi jednakost:
\[(\mathop(lim)_(n\to \infty ) (|F)_n\left(x\right)-F\left(x\right)|=0\ )\]
Primjeri problema za pronalaženje empirijske funkcije raspodjele
Primjer 1
Neka distribucija uzorkovanja ima sljedeće podatke zabilježene pomoću tabele:
Slika 1.
Pronađite veličinu uzorka, kreirajte empirijsku funkciju distribucije i nacrtajte je.
Veličina uzorka: $n=5+10+15+20=50$.
Prema svojstvu 5, imamo da je za $x\le 1$ $F_n\left(x\right)=0$, a za $x>4$ $F_n\left(x\right)=1$.
$x vrijednost
$x vrijednost
$x vrijednost
Tako dobijamo:
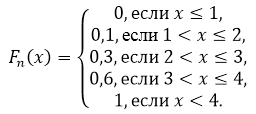
Slika 2.
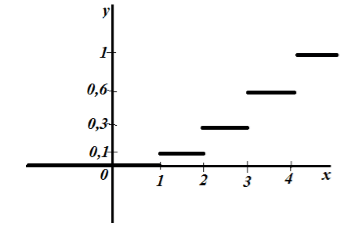
Slika 3.
Primjer 2
Iz gradova centralnog dela Rusije nasumično je odabrano 20 gradova za koje su dobijeni sledeći podaci o cenama prevoza: 14, 15, 12, 12, 13, 15, 15, 13, 15, 12, 15, 14 , 15, 13 , 13, 12, 12, 15, 14, 14.
Kreirajte empirijsku funkciju distribucije za ovaj uzorak i nacrtajte je.
Zapišimo vrijednosti uzorka uzlaznim redoslijedom i izračunajmo učestalost svake vrijednosti. Dobijamo sledeću tabelu:
Slika 4.
Veličina uzorka: $n=20$.
Prema svojstvu 5, imamo da je za $x\le 12$ $F_n\left(x\right)=0$, a za $x>15$ $F_n\left(x\right)=1$.
$x vrijednost
$x vrijednost
$x vrijednost
Tako dobijamo:
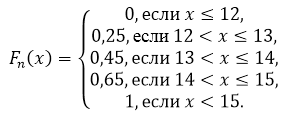
Slika 5.
Nacrtajmo empirijsku distribuciju:
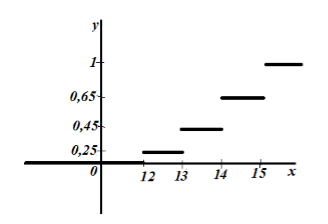
Slika 6.
Originalnost: $92,12\%$.





